6 Muestra PEB 2025
Las pruebas PEB (Pruebas Escolares Bonaerenses) son un programa orientado a mejorar la enseñanza y el aprendizaje de Matemática y Prácticas del Lenguaje en el nivel Primario, tanto en el sector estatal como en el privado, que se puso en marcha en 2022 en la Provincia de Buenos Aires (Subsecretaría 2025, pág. 5).
Desde el punto de vista metodológico que tiene que ver con cuestiones muestrales es pertinente destacar que estas pruebas aspiran a ser realizadas al total de los estudiantes aunque luego se registran sus resultados a través de dos componentes diferentes. Un primer componente censal aunque con datos agregados y un segundo componente muestral con datos nominales. Lo que se detalla a continuación es el proceso de selección muestral de este segundo componente nominal. Primero lo haremos haciendo referencia a la muestra diseñada en 2023 y luego para la de 2025.
6.1 Muestra 2023
Para tener como referencia vamos a intentar representar el método de selección de la muestra que se utiliza desde 2023. Primero la vamos a intentar describir y luego clasificar.
6.1.1 Descripción
Un resumen descriptivo de la misma es la siguiente afirmación:
“En paralelo, se relevaron resultados por estudiante en una muestra probabilística de 680 escuelas. Para cada institución, se solicitó información sobre las respuestas a las actividades de 5 estudiantes seleccionados al azar por las y los docentes de cada sección” (Subsecretaría 2024, pág. 18).
Más en detalle también se afirma “La construcción de la muestra siguió un diseño probabilístico, con selección sistemática de las unidades de muestreo. Previo a la selección, en el marco muestral (nómina de establecimientos de nivel primario) se agruparon los establecimientos en estratos constituidos por el cruce de las variables “dependencia de los establecimientos educativos” (provincial y resto-incluyendo en este último grupo a los establecimientos privados, municipales y nacionales), “porcentaje de estudiantes con AUH”, “presencia o no de jornada completa” y “ámbito”. Luego, se ordenaron los establecimientos por estrato, y se realizó una selección sistemática siguiendo la fracción de muestreo correspondiente” (Subsecretaría 2024, pág. 18).
La descripción anterior alcanzaría para una descricpión de la selección de establecimientos. Pero todavía falta el paso que describe la selección de los estudiantes:
“Para cada sección de los años de estudio evaluados, se solicitó la selección de las/los primeros o últimos estudiantes de la lista (por orden alfabético) que hayan realizado la prueba. En secciones pequeñas (de hasta 10 estudiantes), se requirió la carga de información de todas y todos los estudiantes” (Subsecretaría 2024, pág. 18).
Precaución
No hace falta aclarar que intentar reconstruir una muestra a partir de descripciones en prosa suele ser una actividad arriesgada. Esto se debe a que puede haber confusiones entre los objetivos de la muestra, las acciones que se hicieron en el momento del diseño, las que efectivamente se hicieron en campo y, algo no menos importante, los términos que se usan para describir todo lo anterior.
Hay veces que, aunque parezca paradógico, para alguien que tiene que clasificar a una muestra, es preferible que le digan paso a paso que hicieron en un lenguaje cercano al sentido común sin usar términos propios de la jerga del muestreo. La razón es que en muestreo hay términos que tienen un significado particular que no es el mismo que tienen en otras disciplinas no tan lejanas. Por ejemplo, la palabra “estratificación” tanto en ciencias sociales con en el lenguaje común, suele tener una connotación ordinal, pero en muestreo tiene una connotación muy particular y no necesariamente ordinal. Del mismo modo, alguien con experiencia en análisis de datos entiende por “análisis de clústers (o conglomerados)” algo muy diferente a lo que un muestrista entiende cuando afirma que se realizó un “diseño muestral por conglomerados”.
Lo anterior se complica porque es usual que en los diseños muestrales de las ciencias sociales se hagan diseños polietápicos lo que hace que, por ejemplo, circulen afirmaciones como “muestreo estratificado por conglomerados”. En este caso es posible suponer más de una manera de entender esta afirmación y, a posteriori, más de una manera de haber diseñado o ejecutado esa muestra. Por ejemplo, ¿Se ejecutó primero en campo la parte de los conglomerados y luego se seleccionó por estratos? ¿O se hizo al revés? ¿El orden escrito se refiere a la “ejecución” de los pasos o refiere que momento se “diseñó” cada parte del diseño?
6.1.2 Clasificación
En función de la bibliografía/léxico usado en las secciones anteriores se podría realizar los siguientes comentarios sobre las afirmaciones anteriores:
Antes que nada se observa una particularidad importante. En las PEB efectivamente se va a (casi) todas las unidades de la población de estudiantes. La muestra es solo para ver a cuáles de ellos se “registra” de forma individual. Esto es algo particular porque muchas de las técnicas de muestreo están pensadas para justamente evitar ir a todas las unidades de la población o, en su defecto, para a que a una determinada subpoblación (muestra) se le pueda hacer más preguntas, mediciones, ensayos, etc. que hacen más extensa y profunda y, por lo general, más onerosa la investigación. En lo que acá respecta, lo oneroso no parece la prueba en sí, sino su posterior carga nominal. Esto hace (re)pensar cuál es la población de la muestra:
¿Es la población de estudiantes de todo el nivel primario?
¿Es la población de estudiantes de algunos años específicos de nivel primario (p.e. 3 y 6) a los cuales se les piensa realizar las PEB?
¿Es la población de estudiantes de algunos años específicos de nivel primario (p.e. 3 y 6) a los que efectivamente se les realizó las PEB?
Cabe destacar que en una muestra típica solo se podría decidir entre las primeras dos poblaciones porque, como se comentó arriba, muchas veces uno de los objetivos de la muestra es evitar “ir” o “medir” a cada componente de la población. Sin embargo, en la PEB es posible también decidir que la tercera población sea la más idónea. En efecto, más allá de los posibles problemas de conseguir datos de esa población es claro que no tiene mucho sentido seleccionar estudiantes o secciones que no pertenecen a los establecimientos del “censo” previo.
Dejando estas cuestiones referidas sobre qué población se debería hacer la muestra, el diseño muestral anterior se podría clasificar del siguiente modo:
Un diseño polietápico. En una primera etapa se seleccionan a los establecimientos y luego, en una segunda etapa, se seleccionan a los estudiantes de ese establecimiento a través de sus respectivas secciones. Se suele afirmar que los establecimientos son la unidad de selección primaria y los estudiantes son la unidad de selección secundaria y final. Es importante destacar que los establecimientos cumplen la función de ser un conglomerado en este diseño. En otras palabras, cada establecimiento es como un racimo (cluster) en donde se agrupan secciones y estudiantes. Por cuestiones logísticas es útil seleccionar primero a los establecimientos y luego a los estudiantes que están en su interior. En esta descripción no decimos nada sobre las secciones porque en las descripciones de arriba parecería que ellas no se “seleccionan” aunque más adelante diremos algo sobre esto.
En la primera etapa se hace un diseño muestral estratificado de establecimientos con asignación proporcional mediante un método de selección sistemático. Este diseño primero crea una serie de categorías discretas en las que se presume que la varianza de la/s variables a estimar son algo menor a la varianza promedio de toda la población. Esto permite una ganancia estadística que se puede usar tanto para aumentar la precisión de la estimación o para reducir la cantidad de casos de la muestra. Cuanto se logre esto último es una cuestión que depende de la asociación de las variables seleccionadas para construir los estratos con las variables a estimar. Lo que también (parcialmente) asegura este diseño es que se incluyan en la muestra casos de estratos chicos en tamaño que, mediante un diseño por azar simple, podrían quedar subrepresentados en la muestra.
Decimos que la estratificación es de una asignación proporcional porque la cantidad de casos a seleccionar para cada estrato estará en línea con los tamaños de estratos (no con los tamaños de los establecimientos). Esta muestra, al menos en este paso, intenta replicar la distribución porcentual de los estratos.
Dentro de cada estrato la selección es sistemática, y por lo tanto, probabilística.
En la segunda etapa se aplica una regla que apunta a resolver dos cuestiones diferentes. A “cuantos” y “a quienes” se le van a cargar los datos nominales. Respecto al “cuantos” parece que se resuelve con la regla de cargar todos los casos para las secciones de hasta 10 estudiantes y 5 para el resto. Aunque quizá pase más desapercibido, en esta seguda etapa las secciones cumplen la función de estrato, por lo que la segunda etapa se podría decir que se trata de una selección de estudiantes estratificada por las secciones. En cambio, el “a quienes” se resuelve mediante una regla que selecciona a los “primeros o últimos estudiantes de la lista (por orden alfabético)”. Esta regla tiene el beneficio de ser simple (siendo esto un punto a favor) aunque, en principio, es no probabilística en el sentido que no se trata de selección por azar simple ni sistemática, etc. Su carácter no probabilísitica, no asegura que sea sesgada.
Si la clasificación anterior es correcta se podrían hacer también los siguientes comentarios sobre esa muestra:
La afirmación “Para cada institución, se solicitó información sobre las respuestas a las actividades de 5 estudiantes seleccionados al azar por las y los docentes de cada sección” no parece coincidir con lo realizado. Lo que la muestra selecciona al azar son “establecimientos” pero no “estudiantes”.
La regla sobre la discrecionalidad para que el docente elija los 5 primeros o los 5 últimos induce una dosis de arbitrariedad. La traducción de sí esto en un sesgo (o no) es una cuestión que, de forma aproximada, se puede resolver de forma empírica1. Por otro lado, si se asume que cada docente eligirá siempre al “mejor” grupo (comparando a los 5 primeros versus los 5 últimos) esto no generará un mayor problema en las comparaciónes entre establecimientos, secciones, etc. pero, posiblemente, sesge todos los resultados nominales de las pruebas hacia “arriba”. En principio, esto se podría testear empíricamente comparando las medias de las notas muestrales de cada sección/establecimiento con las medias de las respectivas notas censales de las mismas secciones/establecimientos que entraron en la muestra.
En este diseño, al menos en su primera etapa, los estudiantes de los establecimientos más grandes tienen menores chances de salir en la muestra. Si esto no se corrige mediante ponderadores (ex-ante) o calibradores (ex-post) explícitos esto podría generar un sesgo en los análisis de los resultados. En otras palabras, si cada establecimiento dentro de un estrato tuvo la misma probabilidad de ser elegido de forma independientemente de su matrícula, entonces para esa primera etapa la probabilidad final de selección para un estudiante no es constante.
Algo de esto se corrige en la segunda etapa. Acá influye que la regla de cargar los datos sea por sección y no por establecimiento. Esta regla es la que legitima entender a la muestra anterior como una muestra polietápica en donde en la segunda etapa se usa un diseño estratificado por sección.
A primera vista las secciones podrían ser consideradas como conglomerados en donde seleccionar estudiantes de su interior asumiendo alguna ventaja logística si se selecciona solo una de ellas, por ejemplo, por azar simple. Sin embargo, la acción anterior podría ser conveniente si se asume que las secciones (de un mismo establecimiento) poseen una similar heterogeneidad con respecto a al variable de estudio (p.e. las notas en las PEB). De todos modos, dada la peculariedad de las PEB, la ventaja logística residiría en que hay menos docentes/administrativos que contactar y, no menos importante, menos por controlar después. Acá no habría nada de ventaja logísitica, por ejemplo, desde el punto de vista geográfico. La razón es que, por un lado, “ya se fue” a evaluar a cada estudiante y ahora quedaría decidir los datos de quien se registra de modo nominal.
Si se pasa al otro extremo de seleccionar a todas las secciones del establecimiento elegido (como efectivamente se hizo en la muestra 2024) no hay tal etapa de “selección” a nivel de las secciones. En ese caso las etapas de selección de la muestra son a nivel de los establecimientos y a nivel de los estudiantes, pasando por alto el nivel de las secciones. En efecto, la acción de ir a todas las secciones es como si se hubiera tenido la intención de estratificar debido, quizás, a la sospecha de una posible escasa similitud entre las secciones de un mismo establecimiento. Siguiendo este modo de razonar, el investigador se asegura que los estudiantes sean seleccionados a través de diferentes secciones cumpliendo el deseo de un muestrista que estratifica para que luego se seleccionen los casos dentro de cada estrato. Hace unas líneas se dijo “como si” hubiera tenido la intención de estratificar porque, estrictamente, no sabemos si se estratificó por la razón de reducir el error de la estimación (lo usual en esta técnica) o por si, por el contrario y/o de forma complementaria, por la consecuencia que trae usar este método en las probabilidades de selección de los estudiantes de los establecimientos con mayor matrícula.
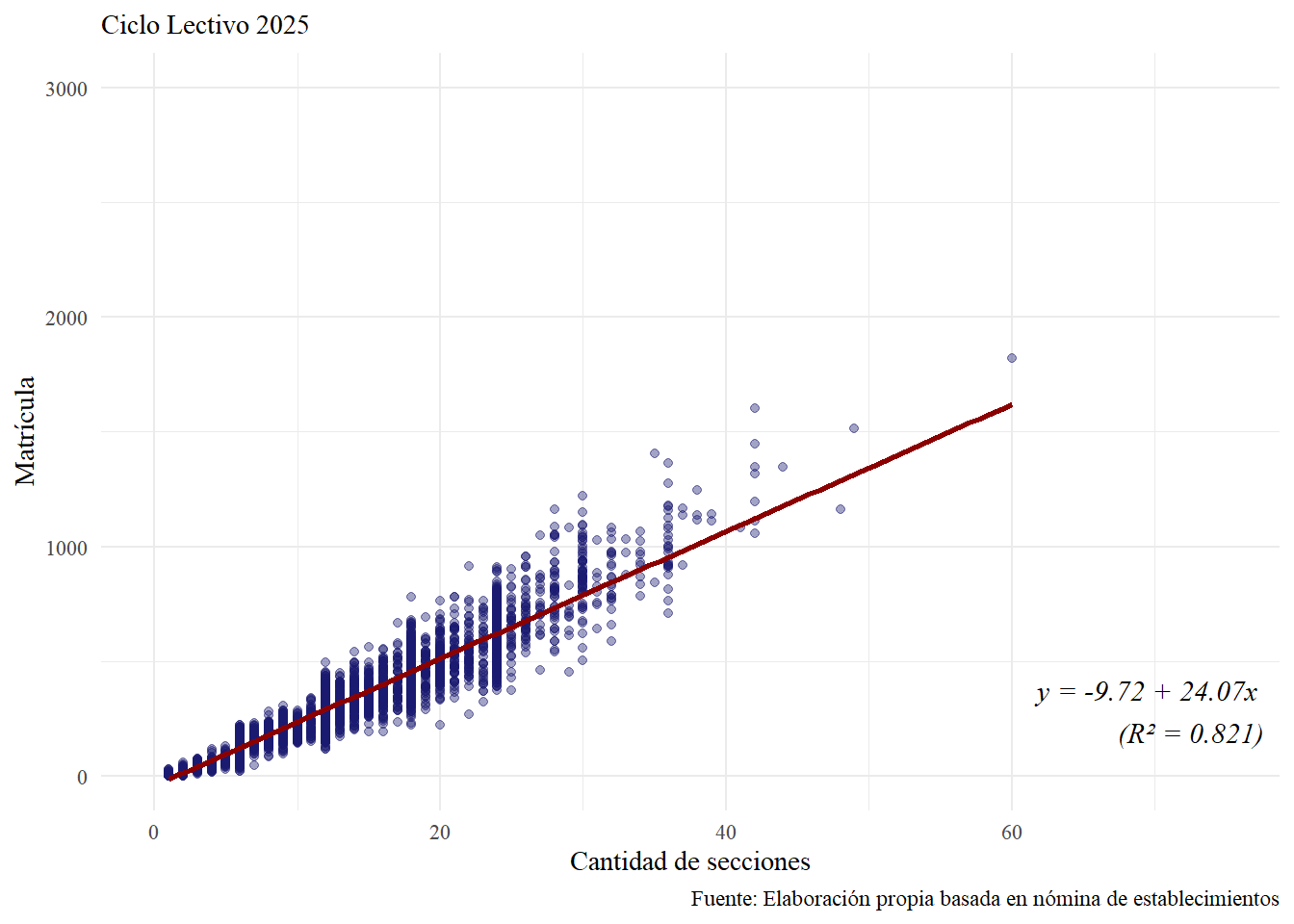
De esta manera, a pesar de no ser la típica consecuencia buscada de la estratificación, aquellos establecimientos con mayor cantidad de secciones (y en general con mayor matrícula) pueden tener una mayor chances de incluir a sus estudiantes en la muestra. En efecto, en la Figura 6.1 se observa una relación estrecha entre el tamaño de la matrícula y la cantidad de secciones del establecimiento.
Sin embargo, hacer un “censo” para las secciones pequeñas hace que se aumente la chance de seleccionar estudiantes de secciones pequeñas que, en general, pertenecen a establecimientos con una menor matrícula. A continuación se muestra en la Tabla 6.1 como las secciones de hasta 10 estudiantes suelen pertenecen a establecimientos con una media y una mediana de la matrícula muy por debajo de la que poseen las secciones más grandes.
| Variable de Matrícula | Chicas N = 7.0261 |
No chica N = 65.8661 |
|---|---|---|
| Matrícula Inicial 2025 | 61,9 16,0 | 461,6 430,0 |
| Desconocido | 4 | 0 |
| 1 Media Mediana | ||
En cualquier caso, las reglas identificadas de la selección de los estudiantes parece tener efectos contrapuestos y es algo difícil de estimar el impacto de cada uno por separado. En particular es difícil de construir ponderadores que anticipen (ex-ante) el sesgo de estas decisiones. Claro que siempre se podrá recurrir al recurso de los calibradores (ex-post) para usarlos al momento del análisis, aunque parece una estrategia algo arriesgada.
Una opción que se puede tener cuenta en estos casos es la inclusión del tamaño de la matrícula en la probabilidad de seleccionar al establecimiento en la primera etapa. Esta estrategia puede tener más de un beneficio. Uno de ellos es que permite una regla simple para la segunda etapa. En efecto, se podría registrar una misma cantidad de estudiantes por establecimiento de forma independiente a la cantidad de secciones. Esto tiene el beneficio adicional que, siguiendo ese diseño, la muestra se vuelve autoponderada lo que facilita los análisis posteriores. Claro está que serán necesario la construcción de calibradores que corrijan la no-respuesta, pero esto es un escenario cualitativamente diferente al descripto en el párrafo anterior. En este contexto, si la muestra no tiene, a posteriori, problemas de no-respuesta, no sería necesario la construcción de calibradores. Sin entrar en detalles (porque en parte se entremezclan un lenguaje de intenciones u objetivos con un lenguaje de métodos) se podría decir que se podrían aprovechar algunas de las características que ofrece el método conocido como muestreo proporcional al tamaño (Sección 3.6).
Por último algunos comentarios van en línea sobre el espectro de inferencias posibles con la muestra 2023. En la biblografía sobre muestreo se suele hacer una distinción clásica entre los estratos y los dominios de estimación (Sección 3.4). Los primeros se suelen usar en el diseño (ex-ante) con la presunción de que en la población existen “clases” discretas que son parecidas en su interior y diferentes entre sí. Si esto es así, su inclusión en el diseño trae mejoras en la precisión en la estimación. En cambio, los dominios tienen que ver con los objetivos o intenciones posteriores del investigador para con la muestra. Por ejemplo, aun el contexto en que se tenga la hipótesis que los establecimientos y los estudiantes rurales poseen fuertes particularidades en contrapoisición a los urbanos. Un escenario es la inclusión de “ambito” como variable para la estratificación y otro escenario es que se quieran realizar inferencias para cada ámbito. En este último caso se dice que los diferentes ámbitos son dominios de estimación de la muestra.
Cuando los estratos con los cuales se diseñan las muestras tienen una cantidad de casos similares la distinción con los dominios se vuelve algo ociosa. En cambio, cuando los estratos tienen diferentes números de casos (p.e. Urbano vs. Rural Agrupado) y luego se desea realizar estimaciones para todos los estratos, es importante la utilidad de la distinción. La razón es que un muestreo estratificado proporcional ayudará poco para tener buenas estimaciones de los dominos pequeños (p.e. Rural Agrupado). En esos casos puede ser preferible un muestreo estratificado con asignación no proporcional óptima (Neyman 1934).
6.1.3 Evaluación actual de la muestra usada en 2024
Desde el momento en que se diseñó la muestra (2023), la población de estudiantes y establecimientos fue cambiando. En especial, es notorio el aumento de establecimientos con jornada completa en los últimos años. Estos cambios poblacionales pueden sugerir dudas acerca de la adecuación de una muestra que fue diseñada para representar a una población con otras características. A pesar de estos supuestos razonables, la muestra actual no parece —al menos en lo que respecta a los establecimientos— haber quedado desfasada para captar el incremento de la jornada completa. Más en particular, se observa una pequeña sobrerepresentación de los establecimientos con jornada completa en esta primera etapa de la muestra. Esto puede deberse a que la expansión de la jornada completa se dío principalmente en establecimientos con matrícula no muy grandes que es justamente el tipo de establecimeintos en donde la muestra anterior parecía tener más casos. A continuación, en la Tabla 6.2, se comparan parámetros poblacionales de los establecimientos con las respectivas estimaciones de la muestra.
| Variable |
Población Total (N = 5884)
|
Muestra 2024(n = 669)
|
|---|---|---|
| N = 5.8841 | N = 6691 | |
| jornada_completa | ||
| NO | 4.757 (81%) | 493 (74%) |
| SI | 1.127 (19%) | 176 (26%) |
| sector | ||
| Estatal | 4.189 (71%) | 487 (73%) |
| Privado | 1.695 (29%) | 182 (27%) |
| ambito | ||
| Rural Agrupado | 372 (6,3%) | 77 (12%) |
| Rural Disperso | 1.064 (18%) | 133 (20%) |
| Urbano | 4.448 (76%) | 459 (69%) |
| matricula_inicial_2025 | 256 (82 – 429) | 234 (75 – 413) |
| Desconocido | 10 | |
| auh_pct | 32 (13 – 50) | 32 (14 – 50) |
| Desconocido | 48 | 4 |
| 1 n (%); Mediana (Q1 – Q3) | ||
6.2 Muestra 2025
Teniendo en mente las características destacadas de la muestra anterior, ahora vamos a pasar a describir los objetivos de la muestra de 2025. En general se conservan muchos de ellos aunque también se agregan otros. Esto hace que, en términos de las técnicas empleadas para llegar a esos objetivos, se exceda el léxico clásico de la estratificación y la conglomeración. Los objetivos son:
Incluir los mismos criterios (actualizados a valores de 2025) que anteriormente se incluyeron en la construcción de los estratos para la construcción de una muestra balanceada. Esto son:
a) Sector (Estatal/Privado)
b) Porcentaje de estudiantes con AUH
c) Presencia de jornada completa
d) Ámbito
La idea de estos es que la muestra (de estudiantes y no de establecimientos) se acerque a los valores de tendencia central de esas variables. En otras palabras, que la muestra se encuentra balanceada en un punto óptimo que reduzca las distancias con las diferentes medidas de tendencia central de las variables anteriores.
Dado que algunas variables numéricas se encuentran disponibles como marco muestral para cada establecimeinto también se va a implementar una muestra (balanceada y) bien distribuida. En otras palabras, el objetivo es también exigir una convergencia con la distribución (esto es, no solo con sus valores de tendencia central) de las siguientes variables:
a) Latitud
b) Longitud
c) Porcentaje de AUH
En términos de las probabilidades de inclusión se esperan cumplir con las siguientes restricciones:
3.1. Otorgarle una mayor probabilidad de entrar a la primera etapa a los establecimientos que entraron en la muestra anterior. La idea es hacer un diseño compatible con una muestra tipo panel que se renueve (aproximadamente) por cuartos en cada edición. De esta manera, ningun establecimiento estaría más de 4 años seguidos y, de manera complementaria, el cuarto que se renueva permitiría ajustar la muestra a los cambios poblacionales sucedidos en el último año.
3.2. Otorgarle una probabilidad de entrar en la primera etapa a los establecimientos en función del tamaño de la matrícula.
3.3. Otorgarle una probabilidad de entrar en la segunda etapa a las secciones en función del tamaño de las mismas.
El punto 3.2 y el punto 3.3 merecen algo más de justificación porque pueden parecer contraintuitivos. En efecto, que en la primera etapa los establecimientos sean seleccionados en función del tamaño de la matrícula permite que, para la segunda etapa de la muestra, se pueda tener una regla simple como la asignación de un número fijo de estudiantes para cada establecimiento. Esto, además, permite (en ausencia de problemas de no-respuesta) hacer análisis con una muestra autoponderada. Más concretamente se aspira a registrar 10 estudiantes de cada establecimiento.
En los establecimientos en donde haya más de una sección, se puede armar un orden de prioridad entre las secciones disponibles y quedarse, en principio, solo con la que mayor prioridad obtenga. Previamente se puede generar un número para cada caso/establecimiento seleccionado que ordene a los establecimientos en función de algún criterio (p.e. matrícula). Algunos establecimientos obtendran un número par y otros tendrán uno impar. En este sentido, una vez sorteada la sección, se usa el valor del número anterior para indicar el modo de selección de los 10 estudiantes. Si ese establecimiento posee un número par, se elige a los primeros 10 estudiantes. Si ese establecimeinto posee un número impar, se elige los últimos 10 estudiantes. Si la sección seleccionada se agota sin llegar a los 10 casos se pasa a la sección siguiente en el orden de prioridad siguiendo luego el mismo criterio de selección de los estudiantes que en la sección anterior.
De este modo se tiene una regla no arbitraria (en el sentido que no decide el docente o el establecimiento qué caso cargar), la misma parece ser probabilística y, de manera derivada, permite trabajar (en ausencia de problemas de no-respuesta) con los datos sin ponderar.
[1] 6766.3 Primera Etapa
Teniendo presente las restricciones anteriores se realizó una primera etapa de la muestra a nivel de establecimientos. Se recuerda que la muestra aspira a ser una muestra de estudiantes más que de establecimientos por lo que algunas desviaciones en esta etapa son más esperables que otras. En particular, es esperable que la media de la matrícula de los establecimientos seleccionados sea mayor a la media de la matrícula de la población de establecimientos. Algunos de los resultados, principalmente en cuanto a valores de tendencia central, se pueden ver en la Tabla 6.3.
| Variable |
Población Total (N = 5836)
|
Muestra 2025(n = 675)
|
|---|---|---|
| N = 5.8361 | N = 6751 | |
| sector | ||
| Estatal | 4.157 (71%) | 438 (65%) |
| Privado | 1.679 (29%) | 237 (35%) |
| ambito | ||
| Rural Agrupado | 371 (6,4%) | 23 (3,4%) |
| Rural Disperso | 1.039 (18%) | 20 (3,0%) |
| Urbano | 4.426 (76%) | 632 (94%) |
| matricula_inicial_2025 | 257 (85 – 430) | 390 (268 – 553) |
| jornada_completa | ||
| NO | 4.711 (81%) | 572 (85%) |
| SI | 1.125 (19%) | 103 (15%) |
| latitud | -34,77 (-35,81 – -34,59) | -34,72 (-34,92 – -34,56) |
| longitud | -58,69 (-59,78 – -58,40) | -58,61 (-58,82 – -58,38) |
| auh_pct | 32 (13 – 50) | 37 (16 – 53) |
| muestra_2024 | ||
| SI | 665 (100%) | 433 (100%) |
| Desconocido | 5.171 | 242 |
| 1 n (%); Mediana (Q1 – Q3) | ||
6.4 Distribución a nivel de establecimientos
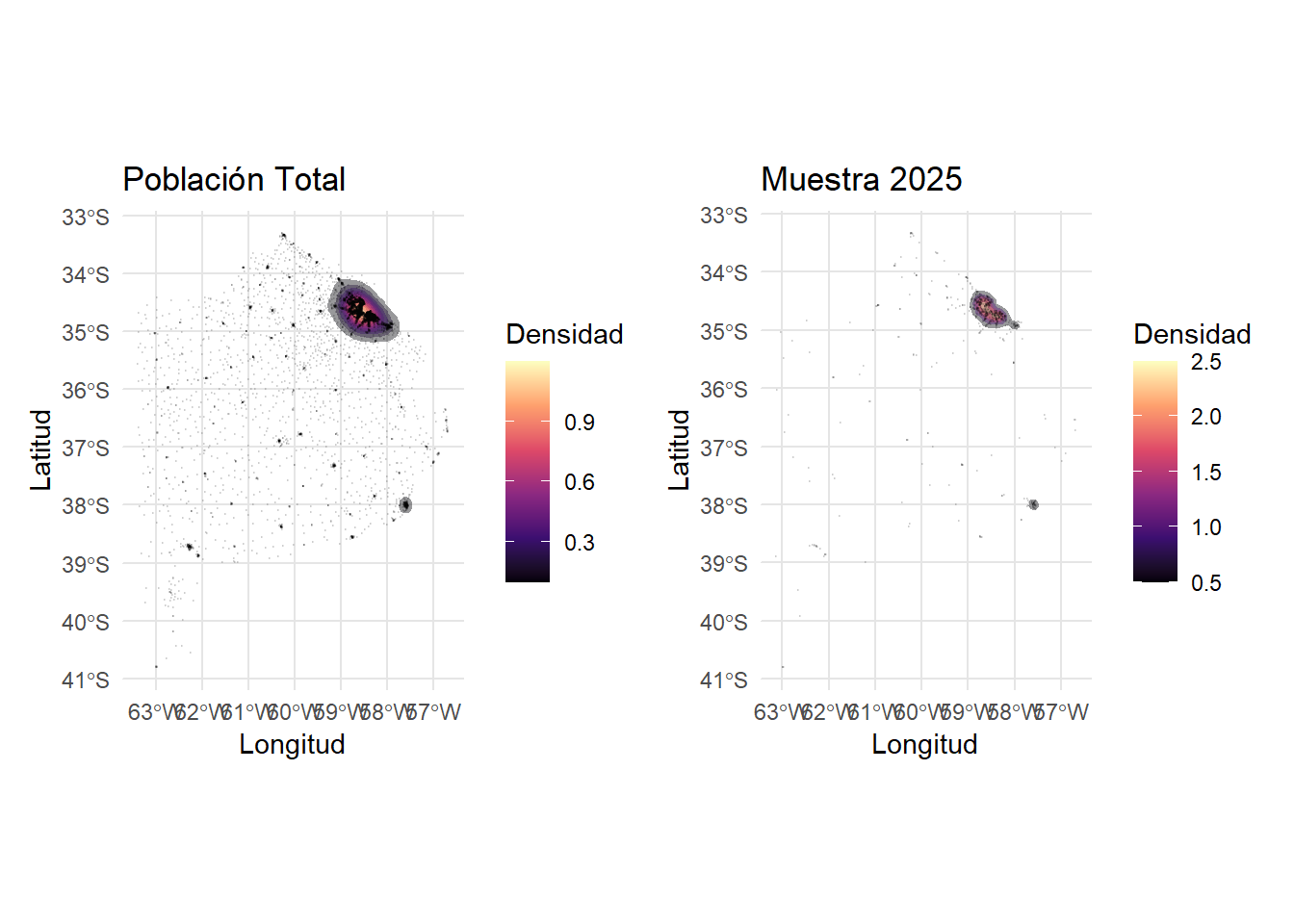
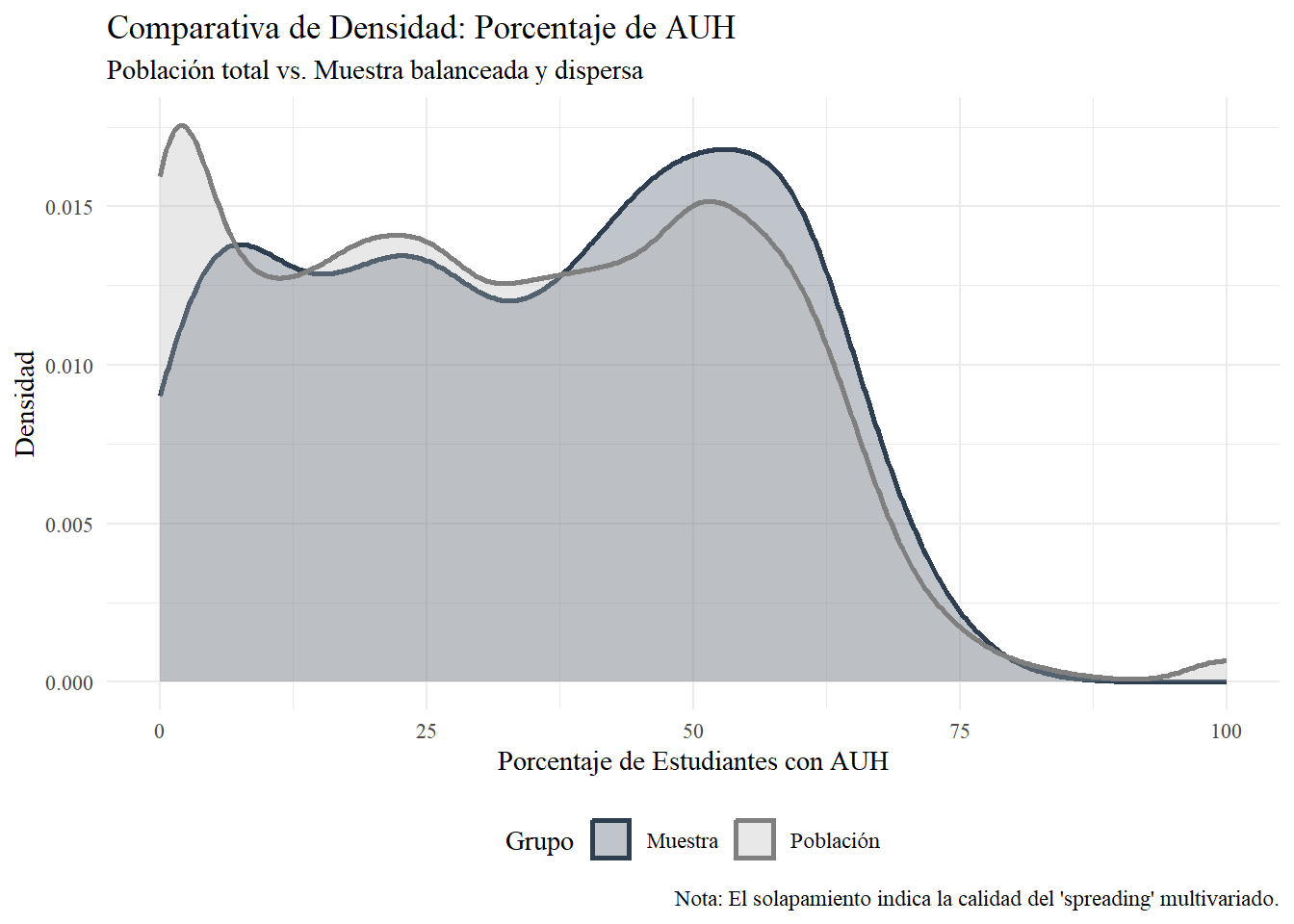
Dado que la muestra no es solo balanceada en sus medidas de tendencia central, sino también en la distribución de otras covariables ahora veremos justamente como la distribución de la muestra difiere, en las variables latitud, longitud (Figura 6.2) y porcentaje de AUH (Figura 6.4), de la distribución de las mismas a nivel del marco muestral.
6.5 Simulación a nivel de estudiantes
Dado que en el actual diseño se emplea una muestra en donde la probabilidad de inclusión deviene en parte del tamaño del establecimiento es esperable, como se anticipó más arriba, encontrar diferencias entre las tendencias centrales de algunas variables consideradas importantes entre la muestra de establecimientos y la población de los mismos. Por esta razón, partiendo del marco muestral de los establecimientos vamos a crear una población sintética de estudiantes en función de la matrícula de cada uno de ellos. Luego vamos a comparar esa población con otra población de estudiantes asumiendo que se seleccionan “x” estudiantes por cada establecimiento seleccionado (10 en este caso).
| Variable | Muestra de Estudiantes (k=10) N = 6.7501 |
Población de Estudiantes N = 1.666.2531 |
|---|---|---|
| sector | ||
| Estatal | 4.380 (65%) | 1.081.271 (65%) |
| Privado | 2.370 (35%) | 584.982 (35%) |
| ambito | ||
| Rural Agrupado | 230 (3,4%) | 22.877 (1,4%) |
| Rural Disperso | 200 (3,0%) | 21.001 (1,3%) |
| Urbano | 6.320 (94%) | 1.622.375 (97%) |
| matricula_inicial_2025 | 390 (268 – 553) | 452 (313 – 624) |
| jornada_completa | ||
| NO | 5.720 (85%) | 1.485.455 (89%) |
| SI | 1.030 (15%) | 180.798 (11%) |
| latitud | -34,72 (-34,92 – -34,56) | -34,72 (-34,88 – -34,57) |
| longitud | -58,61 (-58,82 – -58,38) | -58,59 (-58,79 – -58,36) |
| auh_pct | 37 (16 – 53) | 38 (18 – 54) |
| muestra_2024 | ||
| SI | 4.330 (100%) | 182.586 (100%) |
| Desconocido | 2.420 | 1.483.667 |
| 1 n (%); Mediana (Q1 – Q3) | ||
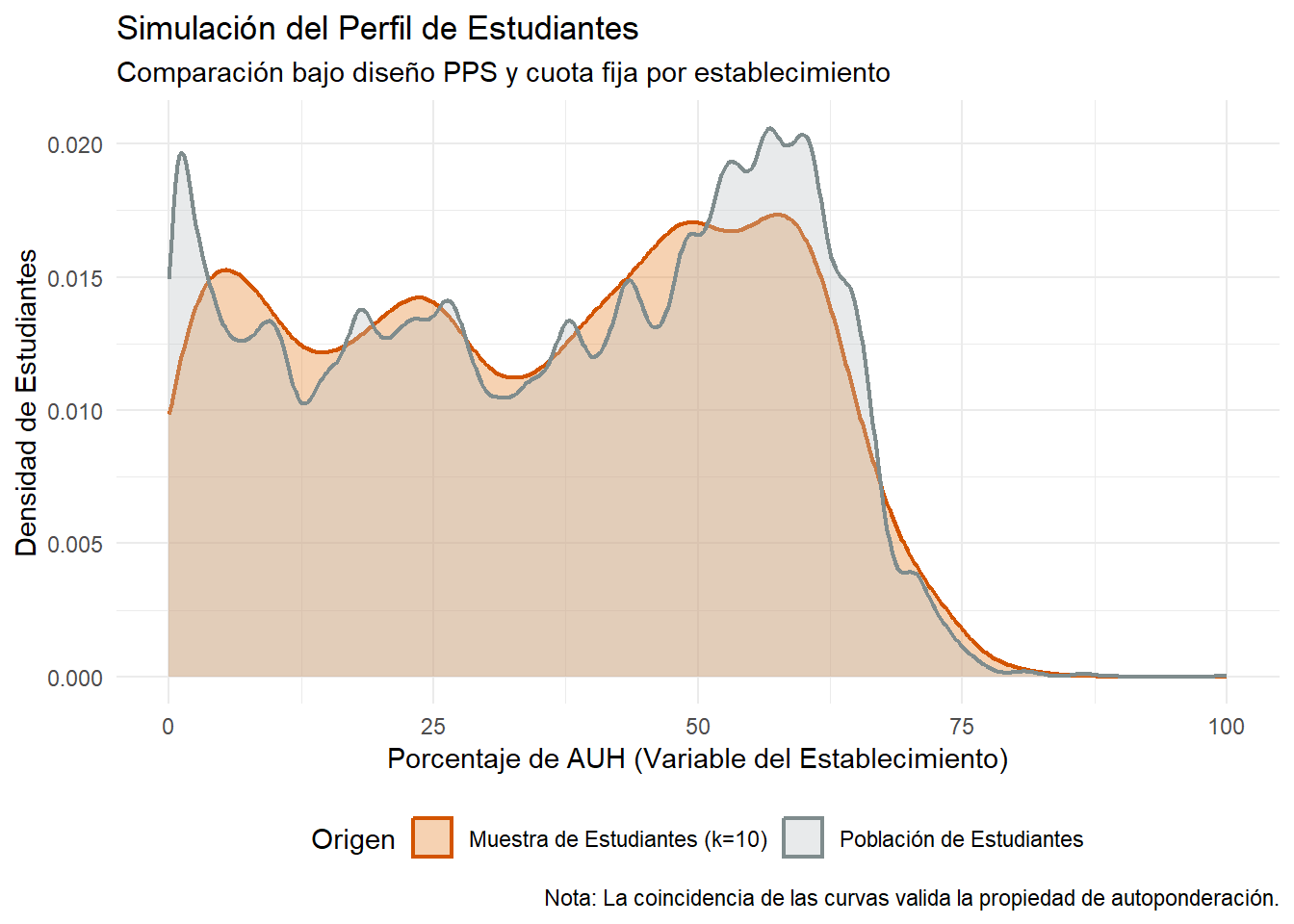
Cabe destacar que si se realiza algún test estadístico entre ambas distribuciones (p.e. Kolmogorov-Smirnov) se observa un aceptable ajuste entre ambas distribuciones lo que sugiere que la muestra logra “copiar” aceptablemente la distribución (y no solo la tendencia central) poblacional de la variable posesión de AUH.
6.6 Segunda etapa
En esta segunda etapa aparece una cuestión particular a considerar. Se trata del tamaño de las secciones de los establecimientos como algo diferente a la cantidad de secciones del mismo. Con respecto a la muestra de 2024, esto es un problema algo nuevo porque el diseño de la muestra 2025 aspira a, efectivamente, seleccionar algunas secciones dentro de los establecimientos en vez de ir a todas.
Antes vimos que si la probabilidad de inclusión de un establecimiento en la primera etapa de la muestra depende del tamaño de la matrícula eso permite que la cantidad de estudiantes a seleccionar en la segunda etapa pueda ser única para todos los establecimientos. Dado que en la mayoría de los establecimientos existe más de una sección para cada año (3ro y 6to) nos encontramos con el problema de como seleccionar a las propias secciones. Expresado en léxico muestral, ahora las secciones se convierten en una segunda etapa de selección. En este sentido, el problema del tamaño de los establecimientos en la primera etapa se traduce al problema del tamaño de cada sección en la segunda etapa. Si solo se realiza un sorteo por azar simple dentro de cada establecimiento para seleccionar a las secciones, los estudiantes de las secciones más grandes van a tener una menor chance de salir en la muestra que los estudiantes de secciones chicas. En funcion de esto podría ser pertinente que, a la hora de realizar el sorteo de las secciones, se incluya en la probabilidad de inclusión el tamaño de la sección (Punto 3.3). Para tener de referencia, los establecimientos seleccionados en 2025 poseen, en promedio, más secciones que los seleccionados en 2024. Si se cuenta los diferentes turnos ahora hay que seleccionar entre 2,8 secciones en cada establecimiento para cada año. En cambio, este valor para la muestra de 2024 fue de alrededor de 2,2 secciones por cada establecimiento/año seleccionado en su respectiva primera etapa.
Sin embargo, el problema no se trata solo de que antes se iba a todas las secciones entre las pocas del establecimiento elegido y ahora a se vaya a algunas entre muchas. Un problema adicional es el siguiente. Supongamos que se tenga en mente la hipótesis que la relación en cuanto al ratio estudiantes/docente sea importante con respecto a los aprendizajes. En ese caso, una regla simple como la de “seleccione siempre a la sección más grande del establecimiento” sería, en presencia de la hipótesis anterior, una regla que, artificialmente, bajaría el promedio de las notas PEB por cenirse a las secciones en donde ese ratio es mayor. La regla anterior se podría mantener si, dentro de cada establecimiento y dentro de cada año seleccionado, hubiera muy poca diferencia de tamaño entre sus diferentes secciones. Esta hipótesis, si bien razonable dentro de ciertos parámetros, es extrema. Por otro lado, asumir que sea usual la situación en donde un establecimiento tenga 3 secciones en 6to grado, de las cuales una tenga un tamaño de 10 estudiantes, otra de 20 y otra de 30, también parece ser algo extremo. Podría ser algo más probable esta situación en los establecimientos de jornada simple en donde habría que seleccionar secciones tanto de la tarde como de la mañana. También puede ser algo más probable de encontrarse esta situación en 6to más que en 3ro. Sin embargo, aun asumiendo que estos últimos casos pueden ser más probables en jornada simple y en 6to es difícil anticipar su peso en el conjunto de las secciones.
Lo anterior puede analizarce de modo empírico de dos modos diferentes. Primero analizaremos la distribución, medida a través de la desviación estándar, de todas las secciones con respecto a su respectiva media de tamaño para su mismo establecimiento y año. Esto nos va a permitir captar la heterogeneridad en función de la misma unidad que se utiliza para calcular la media que, en este caso, es la cantidad de estudiantes. En la Figura 6.6 se observa como, si bien con una distribución normal, existen divergencias con respecto a la media. Esto asegura que, si se seleccionara siempre a las secciones más grandes del tandem establecimiento/año, efectivamente la muestra estaría compuesta casi exclusivamente por secciones que se encuentran por encima de su respectiva media. Claro está que la mayoría de ellas estaría compuesta por secciones que sobrepasan por pocos estudiantes (2 estudiantes) a su respectiva media.
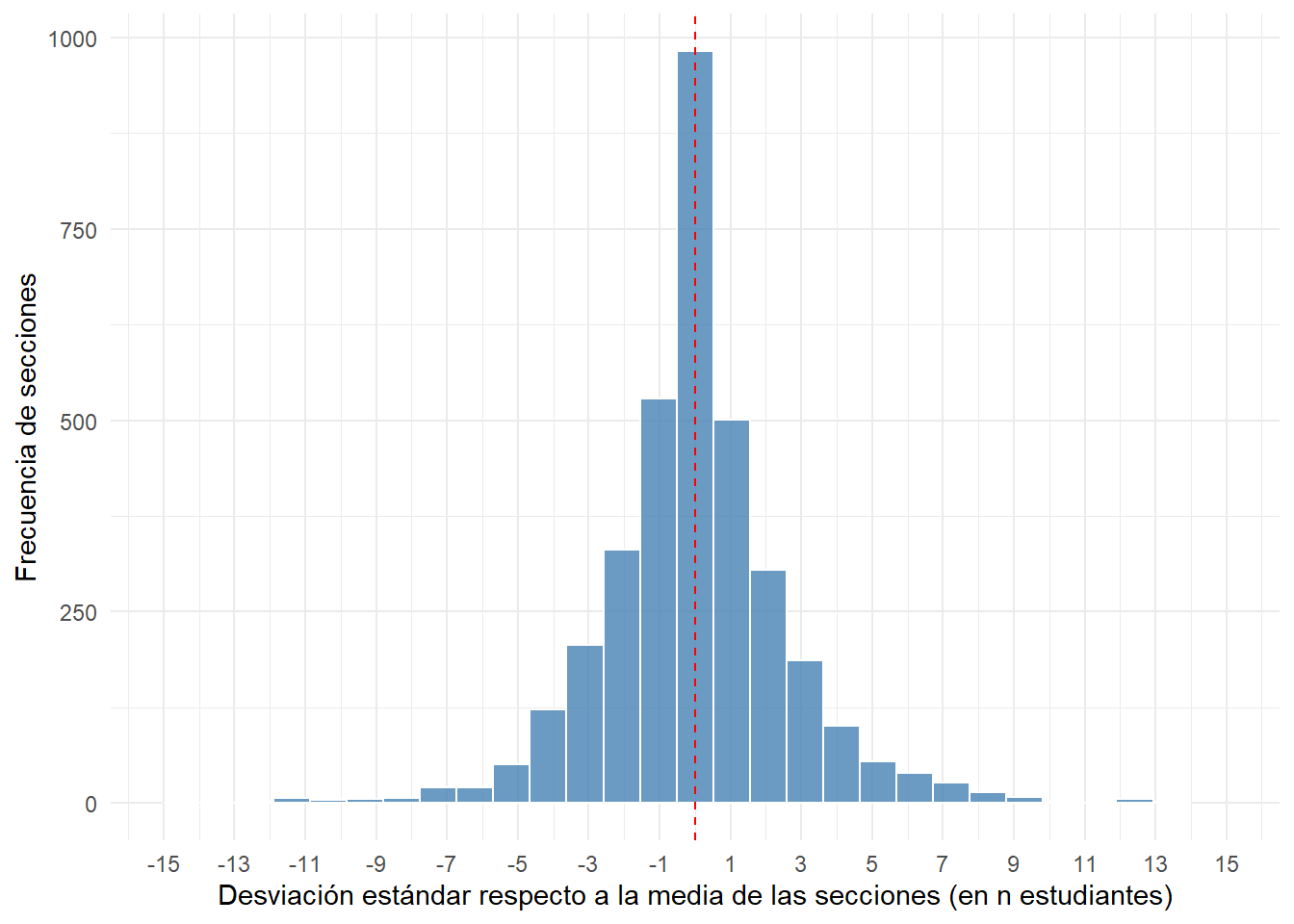
De todos modos, para evitar que la muestra de secciones se pueble exclusivamente de las secciones más mayoritarias, más que implementar la regla simple de “seleccionar la sección más grande” vamos a implementar, como se había anticipado anteriormente, un criterio probabilístico en función del tamaño de la sección. De este modo, a nivel agregado sí se van a seleccionar con mayor probabilidad las secciones más grandes, pero también, en una menor probabilidad, se van a incluir como primera opción algunas secciones que no cumplan ese criterio.
En la Tabla 6.5 puede observarse como al tiempo que se respeta la tendencia central del tamaño de las secciones, la mayoría de las veces (60%) se ha seleccionado a la sección más numerosa aunque, justamente, no siempre. De este modo se respeta el principio que las secciones más numerosas sean más seleccionadas (y de ese modo se equiparan las probabilidades de los estudiantes que están en ellas) pero también se seleccionan secciones no numerosas para de ese modo evitar el sesgo de seleccionar las secciones con mayor ratio de estudiantes/docentes.
| Característica | NO N = 2.3841 |
SI N = 1.3461 |
|---|---|---|
| tamaño | 26 (6)} | 26 (7)} |
| anio | ||
| 3 | 1.196 (50%) | 673 (50%) |
| 6 | 1.188 (50%) | 673 (50%) |
| seccion_mas_grande | ||
| NO | 2.384 (100%) | 534 (40%) |
| SI | 0 (0%) | 812 (60%) |
| 1 Media (DE)}; n (%) | ||
Cuanto (o no) esta regla no probabilística es un sesgo en la muestra es una cuestión empírica. Una manera de generar un testeo podría ser la comparación de las medias porcentuales de la poseción de AUH, a nivel de sección y establecimiento, de los primeros 5 estudiantes con la media del respectivo grupo conformado por la sección y el establecimiento. Esto se puede hacer partiendo de una base nominal de estudiante y ordenando los apellidos por orden alfábetico para cada sección y establecimiento. En el primer caso, se calcula la media de los 5 primeros de cada grupo y en la segunda se incluyen a todos los estudiantes de cada grupo. Al realizar el cálculo a nivel de cada sección no solo se puede testear si ambas medias coinciden, sino que también se puede calcular su respectivo desvío.↩︎