| clave | region | nombre_distrito | localidad | ambito | cueanexo | matricula | secciones | matri_seccion | jornada | porc_auh_2023 | indice_de_vulnerabilidad | prueba2_23_pd_l_a3_irdg | prueba2_23_pd_l_a4_irdg | prueba2_23_pd_l_a6_irdg | prueba2_23_mat_a3_irdg | prueba2_23_mat_a4_irdg | prueba2_23_mat_a6_irdg | prueba1_23_pd_l_a3_irdg | prueba1_23_pd_l_a6_irdg | prueba1_23_mat_a3_irdg | prueba1_23_mat_a6_irdg | sondeo_primero | sondeo_segundo | indice_presencialidad_total | indice_presencialidad_marzo | indice_presencialidad_abril | indice_presencialidad_mayo | indice_presencialidad_junio | indice_presencialidad_julio | indice_presencialidad_agosto | direct_con_0_y_1_anos | direct_con_2_y_3_anos | direct_con_4_a_6_anos | direct_con_7_a_9_anos | direct_con_10_y_11_anos | direct_con_12_a_14_anos | direct_con_15_y_16_anos | direct_con_17_a_19_anos | direct_con_20_y_21_anos | direct_con_22_y_23_anos | direct_con_24_anos_o_mas | mg_con_0_y_1_anos | mg_con_2_y_3_anos | mg_con_4_a_6_anos | mg_con_7_a_9_anos | mg_con_10_y_11_anos | mg_con_12_a_14_anos | mg_con_15_y_16_anos | mg_con_17_a_19_anos | mg_con_20_y_21_anos | mg_con_22_y_23_anos | mg_con_24_anos_o_mas |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0001PP0001 | 01 | La Plata | LA PLATA | Urbano | 060882200 | 678 | 24 | 28.25000 | JS | 43.72414 | 0.1294078 | 69.44444 | 79.11504 | 75.70146 | 63.16872 | 62.00935 | 78.61635 | 68.79167 | 52.70270 | 55.16055 | 81.460177 | 60.74747 | 76.80882 | 0.9366830 | 0.9057018 | 0.9166667 | 0.9090909 | 0.941176470588235 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 11.111111 | 7.407407 | 14.81481 | 14.814815 | 14.814815 | 7.407407 | 3.703704 | 3.703704 | 7.407407 | 7.407407 | 7.407407 |
| 0001PP0002 | 01 | La Plata | LA PLATA | Urbano | 060881800 | 424 | 14 | 30.28571 | JC | 44.71744 | 0.0677139 | 62.32439 | 64.45312 | 60.83333 | 74.54780 | 50.07813 | 63.79630 | 62.61364 | 62.50000 | 58.045977 | 76.0769229999999 | 51.00000 | 66.45370 | 0.8851541 | 0.7481203 | 0.8857143 | 0.9188312 | 0.88235294117647 | 1 | 0.928571428571428 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 5.882353 | 0.000000 | 11.76471 | 17.647059 | 5.882353 | 0.000000 | 5.882353 | 11.764706 | 0.000000 | 0.000000 | 41.176471 |
| 0001PP0003 | 01 | La Plata | ANGEL ETCHEVERRY | Urbano | 060886200 | 464 | 20 | 23.20000 | JS | 67.61711 | 0.7271001 | 54.22980 | 61.34615 | 81.15942 | 64.39394 | 53.61842 | 77.69841 | 57.72152 | 79.44444 | 55.640244 | 88.4154929999999 | 58.39394 | 53.43284 | 1.0000000 | 1.0000000 | 1.0000000 | 1.0000000 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0.000000 | 9.523810 | 14.28571 | 4.761905 | 9.523810 | 4.761905 | 14.285714 | 28.571429 | 0.000000 | 0.000000 | 14.285714 |
3 La domesticación del azar como medio para lograr muestras (aproximadamente) representativas
Si ser muy profundos en cuanto a la teoría del muestreo o en cuanto a su justificación más académica en lo que sigue se intenta recordar que sucede si se realizan muestras aleatorias dentro de una población. Este enfoque tiene mucho que ver con lo que se suele denominar “Design Based Sample” en la literatura sobre muestreo. Básicamente, en línea con la clasificación de Neyman anteriormente utilizada, son muestras que ponen énfasis en el proceso aleatorio de la selección de los casos. Es una escuela clásica dentro del muestreo y tiene muchas subvariantes. Algunas de ellas las veremos más adelante pero ahora nos concentraremos en la parte que tienen en común toda ellas. Para eso vamos a simular que hacemos muchas muestras aleatorias simples sobre una población imaginaria no muy grande (<2000). Primero haremos, o más bien repetiremos, muestras relativamente pequeñas y luego haremos muestras algo más grandes.
Para tener una mejor experiencia de este simulador es aconsejable su ejecución a través de este link.
Con este programa podemos jugar de varias formas. Aquí nos interesa las siguientes.
En primer lugar ver que pasa, en los términos de la figura “datos acumulativos de las muestras” cuando realizamos muchas muestras sobre una misma población (p.e. Población = “Opción 3”). Como veremos, estas distribuciones, en especial si la muestra contiene más de 30 casos, converge hacia un patrón de distribución “normal”. Lo interesante es que esta distribución emerge, con mayor o menor rapidez, de manera independiente de la forma de la población (Ver punto 2). También se puede probar escogiendo diferentes tamaños de las muestras (p.e. Tamaño de la muestra = 30 y 200).
Por otro lado se puede probar que sucede si, se hace el ejercicio anterior en diferentes poblaciones (p.e. con Población = “Opción 6”). Como se observará siempre se obtiene una distribución “normal” aunque en mayor tiempo y con una mayor varianza.
3.1 Población
Como se anticipó en la introducción, nuestra población será una población de establecimientos educativos de gestión estatal de nivel primario. Cada uno de los integrantes de esta población se pueden considerar como unidades de selección, el subconjunto finalmente seleccionado será la muestra y la cantidad de los miembros seleccionados será el tamaño de la muestra. En este caso, como se observa en Tabla tbl-escuelas, se tiene información variada sobre cada una de las escuelas. Como veremos más adelante, tener más información sobre las unidades de selección puede ayudar para la efectiva realización de diferentes diseños muestrales. Algunos de esos diseños servirán cuando el objetivo sea tener una muestra de escuelas (muestreos de una sola etapa) y otros, generalmente más complejos, podrán servir como un primer paso para luego realizar una muestra a estudiantes, directivos, etc. (muestreos polietápicos).
Como puede observarse se trata de una base de escuelas en el sentido que en cada fila hay un establecimiento diferente que contiene una serie de propiedades de los mismos en cada una de las columnas. Algunas de esas propiedades se podrían considerar como intrínsecas de cada escuela (clave, región, ámbito, etc.), otras pueden considerarse como propiedades agregadas de los establecimientos en el sentido que devienen de agregaciones de los estudiantes que son parte de cada escuela (p.e. prueba_x) o de los directivos de los mismos (p.e. direct_x). Estas distinciones son importantes cuando se quiere realizar una muestra porque esto indica límites y posibilidades sobre a qué población se puede realizar una “buena” muestra desde este archivo. En este contexto, la información de este archivo es particularmente buena para realizar una muestra de colegios pero quizá no tan apropiada para realizar una muestra de estudiantes o directivos… al menos si se lo compara, respectivamente, con tener acceso a una lista de estudiantes o una de directivos. Como veremos más adelante, si se tiene en mente este último punto es posible minimizar algunos de esos problemas aplicando algunas estrategias (p.e. seleccionar pocos estudiantes de cada colegio seleccionado) o, de forma más explícita, hacer una muestra proporcional al tamaño de la matrícula de cada establecimiento.1
Por ahora trabajaremos con este archivo para realizar diferentes tipos de muestras de establecimientos educativos. Un plus pedagógico de esta estrategia es que vamos a tener a mano los valores de las estimaciones de las diferentes muestras que se vayan realizando y los respectivos valores de los parámetros poblaciones para comparar resultados. Algunos de esos valores poblacionales se podrán considerar como información secundaria en el sentido que el interés de la muestra no es estimar esos parámetros. Otros de esos valores se los podrá considerar como los parámetros a estimar en la muestra. Esta última situación no es la usual porque si ya se tiene el parámetro poblacional no es necesario la realización de una muestra para su estimación.
Dentro de los parámetros poblacionales vamos a calcular los siguientes:
Matrícula
Secciones
Sondeo primero
Sondeo segundo
Región
Ámbito
Algunas de las variables anteriores son categóricas (región, ámbito) y otras no. Vamos a ver que esto importa porque no es lo mismo estimar un parámetro continuo que uno categórico. Dentro de estos últimos tampoco es lo mismo estimar una variable con 25 categorías (p.e. región) que una variable categórica de 3 categorías (p.e. ámbito).
En la Tabla tbl-parametros_base puede observarse algunos de los valores de estos parámetros. Para el caso de las variables continuas (Matrícula, Secciones, sondeo primero, sondeo segundo) se ha calculado la media junto con los valores del primer y tercer cuartil. En el caso de las variables categóricas (región, ámbito) se han calculado los respectivos porcentajes de cada categoría. Esta distinción es importante porque mientras algunas muestras se esfuerzan por estimar medidas de tendencia central, otras se esfuerzan por estimar medidas de dispersión central y otras intentan hacer ambos tipos de estimaciones. Otra distinción importante es la anteriormente mencionada sobre la población que se quiera muestrear. Por ejemplo, el valor de la media del primer sondeo puede ser útil para estimar si la media de la población de colegios arroja un valor similar que la media de la/s muestra/s realizada/s de esos colegios. Sin embargo, no hay que olvidar que esos datos, sí con ellos se quiere referir a la población de estudiantes, habría que ponderarlos por la matrícula de cada colegio, esto es, habría que calcular su media ponderada.
| Característica | N = 4.1681 |
|---|---|
| matricula | 267,9 |
| Desconocido | 9 |
| secciones | 11,2 |
| Desconocido | 9 |
| sondeo_primero | 57,3 |
| Desconocido | 560 |
| sondeo_segundo | 69,5 |
| Desconocido | 570 |
| region | |
| 01 | 4,5% (189) |
| 02 | 5,4% (223) |
| 03 | 5,0% (210) |
| 04 | 5,1% (213) |
| 05 | 4,7% (194) |
| 06 | 3,6% (148) |
| 07 | 3,3% (138) |
| 08 | 3,6% (149) |
| 09 | 4,9% (205) |
| 10 | 5,4% (224) |
| 11 | 4,0% (166) |
| 12 | 3,7% (155) |
| 13 | 3,1% (131) |
| 14 | 4,1% (169) |
| 15 | 4,2% (174) |
| 16 | 3,0% (125) |
| 17 | 3,2% (133) |
| 18 | 3,8% (160) |
| 19 | 2,8% (118) |
| 20 | 3,8% (159) |
| 21 | 2,8% (117) |
| 22 | 3,7% (153) |
| 23 | 3,7% (153) |
| 24 | 4,7% (196) |
| 25 | 4,0% (166) |
| ambito | |
| Urbano | 65,4% (2.727) |
| Rural Disperso | 25,7% (1.073) |
| Rural Agrupado | 8,8% (368) |
| 1 Media; % (n) | |
Estos parámetros “conocidos” van a tener 2 funciones en este taller. Por un lado, nos van a servir para cotejar, ex-ante, la media de las medias muestrales realizadas con azar simple y, por otro lado, nos pueden servir, ex-post, para mejorar las muestras concretas efectivamente obtenidas. Esto último, más allá de las técnicas específicas que se utilicen, es importante por lo siguiente:
Las muestras que se hacen en la realidad son “únicas” o “individuales” en el sentido que no se repiten. En cambio, una buena parte de la teoría del muestreo supone una distribución de muestras (como las simulaciones anteriores en donde se realizaban varias muestras de una misma población). La mayoría de las veces el investigador que sale a campo dispone de solo una muestra y el objetivo es que “esa” muestra (y no cualquier otra posible) sea de las mejores y no de las peores. En este sentido, es útil tener herramientas que permitan saber si la muestra es de las buenas o de las malas y, si se trata de este último caso, como mejorarlas.
3.2 Muestreo por azar simple
Dentro de los métodos aleatorios el método del azar simple (random sampling) es un método tradicional y particularmente útil desde un punto de vista pedagógico para comenzar ya que muchos otros métodos son variaciones (usualmente más complejas) de este. El método del azar simple es el que intuitivamente se ha utilizado en la simulación anterior.
Desde una perspectiva amplia, en la actualidad se podría afirmar que este método de muestreo se encuentra en el medio de un continuo de situaciones en cuando al grado de información exigida para su realización. Lo “único” que pide es una lista de “contactos” de la población que se quiere analizar. La razón por la que “único” se encuentra entre comillas es la siguiente: La necesidad de la una lista puede ser algo exigente en algunas investigaciones (p.e. poblaciones invisibles) aunque algo insuficiente para otras (p.e. diseños con muestras estratificadas). La idea de “contacto” es algo polisémica, pero aquí apunta a que el caso seleccionado se pueda contactar de alguna forma (p.e. dirección de domicilio, mail, celular, etc.) para realizarle las observaciones/mediciones correspondientes.
A continuación vamos a realizar unas 1000 muestras de 300 casos cada una sobre el total de las 4168 escuelas. Esto es una relación entre el tamaño de la población y la muestra de casi el 14%. Hacemos esta cantidad de muestras para observar la distribución de los valores de las medias de cada muestra y ver si sucede algo similar a lo encontrado en el simulador anterior. Para facilitar la comparación lo haremos solo con las variables numéricas y dejaremos de lado las categóricas como Ámbito y Región. El resultado de estas simulaciones se puede observar en la Tabla tbl-medias_muestrales_azar_simple.
| Característica | N = 1.0001 |
|---|---|
| matricula | 269 (15) |
| secciones | 11,18 (0,49) |
| sondeo_primero | 57,27 (0,95) |
| sondeo_segundo | 69,53 (0,91) |
| 1 Media (DE) | |
Como se puede comparar entre Tabla tbl-parametros_base y Tabla tbl-medias_muestrales_azar_simple los valores entre los parámetros poblacionales y la media de las estimaciones muestrales coincide. No solo eso. También podemos chequear que la distribución de esas medias sigue una distribución aproximadamente normal. Esto es lo que precisamente hacemos en la Figura fig-medias_muestrales_azar_simple.
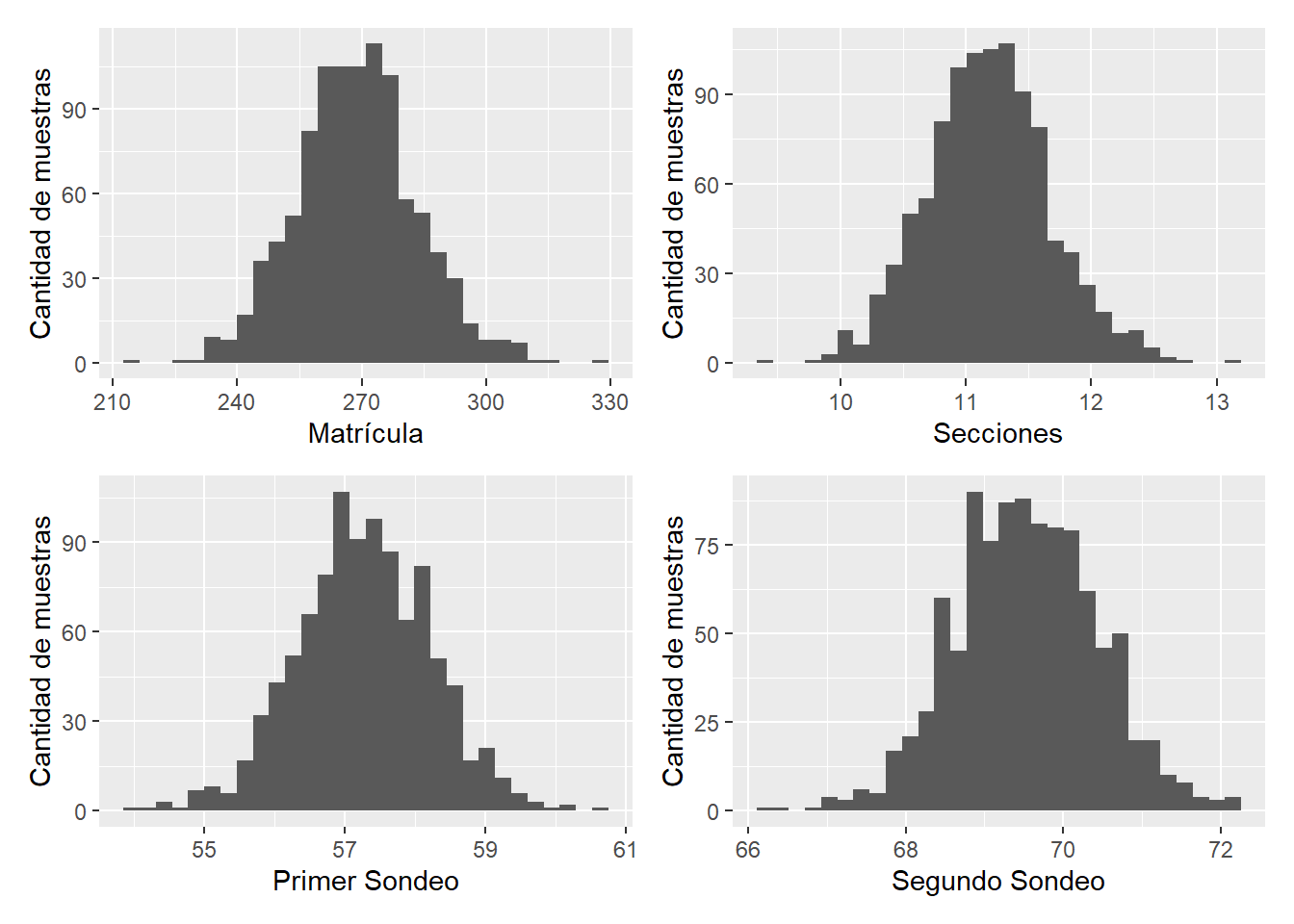
En la figura anterior se observa que la distribución de las 1000 muestras que tomamos, si bien se aproximan, no son idénticas a una distribución normal. Seguramente, si haríamos más muestras nos acercaríamos aún más a una distribución muestral pero quizá este ejemplo baste para explicitar el siguiente punto: Si haríamos muchas muestras vamos a saber con cierta seguridad que la media de las muestras será aproximadamente similar al parámetro poblacional. Sin embargo, quedan abiertas otras preguntas como ¿Qué sucede si solo tomamos una sola muestra? ¿Cómo sabemos si nuestra (única) muestra es de las buenas o de las malas? ¿Cómo sabemos que nuestra muestra no es alguna de las que están en el extremo izquierdo o derecho de la Figura fig-medias_muestrales_azar_simple?
Ahí es donde entra la ayuda de las librerías específicas. En la introducción se había comentado sobre la existencia de librerías específicas para el análisis de datos muestrales. Estas librerías le van a prestar atención a varios detalles del proceso de selección y nos van a pedir que los explicitemos. Por ejemplo, El tipo de muestras que nos van a interesar generalmente son “sin reemplazo” en el sentido que no queremos que, por ejemplo, un mismo colegio aparezca dos veces seleccionado en una muestra de colegios. También, casi todas las librerías de este estilo, nos van a pedir información de algunos totales de la población para construir ponderadores y otras librerías nos a pedir esos ponderadores utilizarlos en el análisis de los datos. En el caso de una muestra aleatoria simple ese ponderador, al menos en la fase de diseño, suele ser la probabilidad inversa de haber ingresado en la muestra (\(N/n\), donde \(N\) es el tamaño de la población y \(n\) el tamaño de la muestra). En este tipo de diseño el valor del ponderador es el mismo para todas las unidades seleccionadas.
| Característica |
Azar simple
|
Parámetro Pob.
|
|
|---|---|---|---|
| N = 4.1681 | 95% CI | N = 4.1682 | |
| matricula | 276,6 (2,9) | 271, 282 | 267,9 |
| secciones | 11,6 (0,1) | 11, 12 | 11,2 |
| sondeo_primero | 56,2 (0,2) | 56, 57 | 57,3 |
| Desconocido | 472 | 560 | |
| sondeo_segundo | 69,8 (0,2) | 69, 70 | 69,5 |
| Desconocido | 556 | 570 | |
| region | |||
| 01 | 2,3% (n=7) | 2,0%, 2,7% | 4,5% (189) |
| 02 | 6,3% (n=19) | 5,8%, 6,9% | 5,4% (223) |
| 03 | 5,3% (n=16) | 4,9%, 5,8% | 5,0% (210) |
| 04 | 7,0% (n=21) | 6,5%, 7,6% | 5,1% (213) |
| 05 | 2,7% (n=8) | 2,3%, 3,0% | 4,7% (194) |
| 06 | 3,7% (n=11) | 3,3%, 4,1% | 3,6% (148) |
| 07 | 3,7% (n=11) | 3,3%, 4,1% | 3,3% (138) |
| 08 | 5,3% (n=16) | 4,9%, 5,8% | 3,6% (149) |
| 09 | 6,7% (n=20) | 6,1%, 7,2% | 4,9% (205) |
| 10 | 6,7% (n=20) | 6,1%, 7,2% | 5,4% (224) |
| 11 | 4,3% (n=13) | 3,9%, 4,8% | 4,0% (166) |
| 12 | 2,3% (n=7) | 2,0%, 2,7% | 3,7% (155) |
| 13 | 2,7% (n=8) | 2,3%, 3,0% | 3,1% (131) |
| 14 | 4,0% (n=12) | 3,6%, 4,4% | 4,1% (169) |
| 15 | 3,3% (n=10) | 3,0%, 3,7% | 4,2% (174) |
| 16 | 2,0% (n=6) | 1,7%, 2,3% | 3,0% (125) |
| 17 | 3,3% (n=10) | 3,0%, 3,7% | 3,2% (133) |
| 18 | 3,0% (n=9) | 2,7%, 3,4% | 3,8% (160) |
| 19 | 2,7% (n=8) | 2,3%, 3,0% | 2,8% (118) |
| 20 | 3,7% (n=11) | 3,3%, 4,1% | 3,8% (159) |
| 21 | 2,0% (n=6) | 1,7%, 2,3% | 2,8% (117) |
| 22 | 4,0% (n=12) | 3,6%, 4,4% | 3,7% (153) |
| 23 | 4,7% (n=14) | 4,2%, 5,1% | 3,7% (153) |
| 24 | 3,0% (n=9) | 2,7%, 3,4% | 4,7% (196) |
| 25 | 5,3% (n=16) | 4,9%, 5,8% | 4,0% (166) |
| ambito | |||
| Urbano | 67,0% (n=201) | 66%, 68% | 65,4% (2.727) |
| Rural Disperso | 20,3% (n=61) | 19%, 21% | 25,7% (1.073) |
| Rural Agrupado | 12,7% (n=38) | 12%, 13% | 8,8% (368) |
| Desconocido | 9 | ||
| Desconocido | 9 | ||
| Abreviacion: CI = Intervalo de confianza | |||
| 1 Media (SE); % (n=n (unweighted)) | |||
| 2 Media; % (n) | |||
Ahora que estamos analizando solo una muestra podemos empezar a ver algunas distancias entre los parámetros poblaciones y las estimaciones que surgen de la muestra. Esto es especialmente más notorio en los casos de las categorías menos difundidas de las variables categóricas como puede ser algunas de las regiones.
3.3 Muestreo Sistemático
El muestreo sistemático no ofrece muchas diferencias apreciables de cálculo con el azar simple aunque tiene una diferencia logística importante. No es necesario tener en el momento del diseño una lista centralizada de “contactos” a quien seleccionar. Esto hace que el muestreo sistemático, especialmente en muestras polietápicas, sea un buen candidato a aplicar en las últimas instancias de selección en donde cada encuestador, evaluador o data entry, de manera descentralizada, sí tiene acceso, in situ, a esa información. Es importante, de todos modos, explictar el supuesto que la lista en cuestión no esconda un sesgo particular en su orden o, ante esta presuposición, poder reordenarla bajo algún criterio que fuerce el azar. De todos modos, ante la existencia de algún patrón subyacente, el muestreo sistemático, versus opciones como “elegir a los x primeros (o últimos)” parece mejor equipado. Sin embargo, estas últimas opciones tienen el beneficio de (usualmente) ser más simples de implementar para el operador final.
Como ejemplo podemos analizar la siguiente situación. Se quiere realizar una muestra de estudiantes y a) no se cuenta con información nominal en el momento del diseño de la muestra aunque b) sí se cuenta con una buena base de los colegios y c) se asume que dentro de cada colegio sí existe acceso a una lista de contactos de los estudiantes. En este contexto, se puede sortear una cantidad de colegios en una primera etapa (p.e. mediante la técnica sec-pps) y luego, en una segunda etapa, se puede indicar al directivo, encuestador, etc. de cada escuela seleccionada que, una vez con acceso a la lista de estudiantes, seleccione una \(X\) cantidad de los mismos. Para realizar esa última selección el proceso será sortear al primer estudiante, seleccionarlo y luego, desde allí, saltar \(K\) estudiantes para seleccionar al segundo estudiante y así sucesivamente. En general, \(K\) representa el cociente entre el tamaño de la población a seleccionar \(N\) como el tamaño de la lista de estudiantes del colegio seleccionado y el tamaño de la muestra \(n\) como la cantidad de estudiantes que se quiere seleccionar de esa lista.
\[K = \frac{N}{n}\]
Siguiendo este ejemplo, supongamos que el encuestador tenga que elegir 5 estudiantes de una lista de 50. En ese caso se podría aplicar el siguiente código:
Cambiando lo que haya que cambiar, el código anterior también se podría aplicar si se quiere utilizar para seleccionar los 300 establecimientos que antes se habían seleccionado con el diseño del azar simple.
3.4 Muestreo Estratificado
El muestreo estratificado es un tipo de muestreo que se realiza sobre la base de estratos que, en principio, cumplen el criterio de que sean parecidos en su interior y diferentes entre ellos. Otra característica distintiva de los estratos es que estos son discretos, esto es, pueden tener, a lo sumo, un orden entre ellos, pero los límites entre ellos son puntuales más que continuos.
Si se recuerda los comentarios realizados en la introducción, cuanto menos heterogeneidad exista entre las unidades a seleccionar menor es el problema de la representatividad. Esto es precisamente lo que intenta aprovechar la idea del muestreo estratificado. En el extremo, si todos los miembros de cada estrato son iguales entre sí y los tamaños o cantidad de casos de cada estrato también son iguales entre sí, solo habría que seleccionar a un caso por estrato como razón suficiente para obtener una muestra representativa de la población. Si los tamaños de los estratos fueran diferentes también se podría seleccionar un caso por estrato, pero la condición para que esta muestra sea representativa es que luego se incluyan ponderadores diferentes para cada estrato de la muestra en función de la inversa de la probabilidad de entrar en la muestra. Esta diferencia, es la diferencia central entre el muestreo estratificado proporcional y el no proporcional con asignación óptima que veremos más adelante.
Para que el muestreo estratificado produzca ventajas (en comparación con el azar simple) los estratos deben tener una heterogeneidad interna menor a la heterogeneidad del conjunto de la población aunque aquella se encuentre lejos del ejemplo extremo del párrafo anterior. Los estratos conforman subpoblaciones mutuamente excluyentes y exhaustivas de toda población aunque se pueden construir los mismos en función de datos categóricos, agregaciones de datos continuos (p.e. agrupaciones de años de antigüedad) o espaciales (p.e. Regiones). En una base de datos educativa puede haber muchas variables que pueden ser considerados como estratos. En este caso, a modo de ejemplo, nos quedaremos con “Ámbito” que posee 3 categorías que asumimos, como diría Platón en el Fedro, que cortan la realidad por sus articulaciones naturales (Platón 2002 [370AVC], pág. 55). Por otro lado, utilizar “Ámbito” como estrato tiene otra virtud pedagógica que deviene de la diferente distribución porcentual de cada categoría. Esto lo hace un buen candidato para mostrar la utilidad del muestreo estratificado en su versión proporcional y no proporcional, ya que la categoría “Rural Agrupado” posee un menor porcentaje de casos y, a igualdad de otras condiciones, veremos como eso dificulta su posterior análisis. Veremos también que para decidir entre estos tipos de diseño también será útil indagar en el significado de un término clásico del muestreo como es el “dominio” de estimación.
A veces los estratos se construyen con base en antecedentes teóricos, pero nada impide que estos sean constructos estadísticos con un significado no muy claro como los que se pueden producir luego de un análisis de clústers (Everitt et al. 2011). Tampoco la técnica tiene una limitación en cuanto a la cantidad de categorías. Cabe aclarar que cualquier estrato debe ser capaz de construirse tanto a nivel poblacional como posible de identificarse/seleccionarse a nivel muestral. En este sentido, más allá si tiene un origen más teórico o estadístico es claro que esta técnica exige tener acceso empírico a una mayor cantidad de variables en comparación con, por ejemplo, el azar simple.
3.4.1 Estratos con asignación proporcional
En este subtipo de muestreo estratificado utilizaremos la variable “Ámbito” como estrato y respetaremos, aproximadamente, la distribución que ese estrato posee en la población. Decimos “aproximadamente” porque aquí siempre existe un factor de redondeo que deviene de la necesidad de realizar la muestra sobre una cantidad de casos discretos. Esta última necesidad hace que, al igual que cuando se intenta respetar las proporciones de los votos de una elección para la renovación de bancas de la Cámara de Diputados, casi siempre existan pequeñas diferencias entre las proporciones poblacionales y las muestrales.
Seleccionada la muestra ahora le especifico los detalles del diseño mediante la librería survey o srvyr.
Y luego realizo la Tabla tbl-estratificado_teo_prop con la información de algunas variables y esa misma tabla lo comparo con los valores de la Tabla tbl-azar_simple que refería al diseño con azar simple.
| Característica |
Estratificado P.
|
Azar simple
|
||
|---|---|---|---|---|
| N = 4.1681 | 95% CI | N = 4.1681 | 95% CI | |
| matricula | 262,3 (1,9) | 258, 266 | 276,6 (2,9) | 271, 282 |
| Desconocido | 28 | |||
| secciones | 10,9 (0,1) | 11, 11 | 11,6 (0,1) | 11, 12 |
| Desconocido | 28 | |||
| sondeo_primero | 57,9 (0,2) | 58, 58 | 56,2 (0,2) | 56, 57 |
| Desconocido | 712 | 472 | ||
| sondeo_segundo | 69,8 (0,2) | 69, 70 | 69,8 (0,2) | 69, 70 |
| Desconocido | 572 | 556 | ||
| region | ||||
| 01 | 2,7% (n=8) | 2,3%, 3,0% | 2,3% (n=7) | 2,0%, 2,7% |
| 02 | 6,3% (n=19) | 5,8%, 6,9% | 6,3% (n=19) | 5,8%, 6,9% |
| 03 | 6,3% (n=19) | 5,8%, 6,9% | 5,3% (n=16) | 4,9%, 5,8% |
| 04 | 6,3% (n=19) | 5,8%, 6,9% | 7,0% (n=21) | 6,5%, 7,6% |
| 05 | 4,6% (n=14) | 4,2%, 5,1% | 2,7% (n=8) | 2,3%, 3,0% |
| 06 | 4,0% (n=12) | 3,6%, 4,4% | 3,7% (n=11) | 3,3%, 4,1% |
| 07 | 4,3% (n=13) | 3,9%, 4,8% | 3,7% (n=11) | 3,3%, 4,1% |
| 08 | 3,3% (n=10) | 3,0%, 3,7% | 5,3% (n=16) | 4,9%, 5,8% |
| 09 | 4,0% (n=12) | 3,6%, 4,4% | 6,7% (n=20) | 6,1%, 7,2% |
| 10 | 4,0% (n=12) | 3,6%, 4,5% | 6,7% (n=20) | 6,1%, 7,2% |
| 11 | 2,7% (n=8) | 2,3%, 3,0% | 4,3% (n=13) | 3,9%, 4,8% |
| 12 | 3,0% (n=9) | 2,7%, 3,4% | 2,3% (n=7) | 2,0%, 2,7% |
| 13 | 3,7% (n=11) | 3,3%, 4,1% | 2,7% (n=8) | 2,3%, 3,0% |
| 14 | 5,0% (n=15) | 4,6%, 5,5% | 4,0% (n=12) | 3,6%, 4,4% |
| 15 | 4,4% (n=13) | 3,9%, 4,8% | 3,3% (n=10) | 3,0%, 3,7% |
| 16 | 2,3% (n=7) | 2,0%, 2,7% | 2,0% (n=6) | 1,7%, 2,3% |
| 17 | 5,0% (n=15) | 4,6%, 5,5% | 3,3% (n=10) | 3,0%, 3,7% |
| 18 | 5,0% (n=15) | 4,6%, 5,5% | 3,0% (n=9) | 2,7%, 3,4% |
| 19 | 2,3% (n=7) | 2,0%, 2,7% | 2,7% (n=8) | 2,3%, 3,0% |
| 20 | 4,0% (n=12) | 3,6%, 4,5% | 3,7% (n=11) | 3,3%, 4,1% |
| 21 | 1,3% (n=4) | 1,1%, 1,6% | 2,0% (n=6) | 1,7%, 2,3% |
| 22 | 4,7% (n=14) | 4,3%, 5,2% | 4,0% (n=12) | 3,6%, 4,4% |
| 23 | 5,0% (n=15) | 4,6%, 5,5% | 4,7% (n=14) | 4,2%, 5,1% |
| 24 | 2,7% (n=8) | 2,3%, 3,0% | 3,0% (n=9) | 2,7%, 3,4% |
| 25 | 3,0% (n=9) | 2,7%, 3,4% | 5,3% (n=16) | 4,9%, 5,8% |
| ambito | ||||
| Urbano | 65,4% (n=197) | 65%, 65% | 67,0% (n=201) | 66%, 68% |
| Rural Disperso | 25,7% (n=77) | 26%, 26% | 20,3% (n=61) | 19%, 21% |
| Rural Agrupado | 8,8% (n=26) | 8,8%, 8,8% | 12,7% (n=38) | 12%, 13% |
| Abreviacion: CI = Intervalo de confianza | ||||
| 1 Media (DE); % (n sin ponderar) | ||||
Una característica importante de este tipo de muestreo es que sus factores de expansión o expansores, al menos en la fase de diseño, son iguales para todos los estratos. Esto suele ser una pequeña ventaja para el momento del análisis ya que requiere mano de obra algo menos especializada.
3.4.2 Estratos con asignación no proporcional
En el tipo de diseño anterior hubo una variable (Ámbito) que se usó para estratificar la muestra. En ese caso, salvo variaciones menores debido a los factores de redondeo antes comentados, las proporciones de la muestra respetan las proporciones poblacionales. Eso es lo que precisamente se intenta modificar con el muestreo con una asignación no proporcional. Usualmente, la idea que está detrás de esta estrategia es poder reducir el desvío estándar de aquellos estratos que más suman al desvío estándar de toda la muestra. El desvío estándar de cada estrato es una función entre la heterogeneidad propia de cada estrato (p.e. que tán iguales son entre sí los establecimientos “Rural Agrupado”) con la cantidad de casos de ese estrato (a mayor cantidad de casos menor desviación estándar). Si en la muestra se respeta la proporción original de la población (aun en el caso de que los establecimientos de ámbitos urbanos tengan una misma heterogeneidad que el resto) es claro que los estratos rurales poseen una distribución muy baja y, por lo tanto, nos vamos a quedar con pocos casos en la muestra y, de manera derivada, con un alto error estándar en esos análisis. La propuesta original de Neyman (Neyman 1934) justamente trata de como asignar de manera eficiente (desde el punto de vista estadístico) la cantidad de casos a cada estrato, haciendo que, para nuestro ejemplo, los estratos rurales se encuentren sobrerrepresentados y los urbanos subrepresentados. Esta estrategia permite que, para una igual cantidad de casos que un muestreo estratificado proporcional, se puedan hacer inferencias (bastante) más confiables para dominios de estimación más pequeños a cambio de perder (un poco) de confiabilidad en los dominios de estimación más grandes2.
La contraparte de esta ventaja es que ahora es necesario construir expansores diferentes para cada estrato para que se le devuelva la probabilidad que se encontraba en la población. En este sentido, el factor de expansión del estrato urbano será mayor al de los estratos rurales.
Aquí, para extremar esta lógica, vamos a realizar una muestra como si la distribución de la variable Ámbito fuera igual para sus 3 categorías.
| Característica |
Estratificado P
|
Estratificado no P
|
||
|---|---|---|---|---|
| N = 4.1681 | 95% CI | N = 4.1681 | 95% CI | |
| matricula | 262,3 (1,9) | 258, 266 | 271 (2) | 267, 275 |
| Desconocido | 28 | 38 | ||
| secciones | 10,9 (0,1) | 11, 11 | 11 (0) | 11, 11 |
| Desconocido | 28 | 38 | ||
| sondeo_primero | 57,9 (0,2) | 58, 58 | 57 (0) | 57, 58 |
| Desconocido | 712 | 577 | ||
| sondeo_segundo | 69,8 (0,2) | 69, 70 | 70 (0) | 69, 70 |
| Desconocido | 572 | 533 | ||
| region | ||||
| 01 | 2,7% (n=8) | 2,3%, 3,0% | 4,2% (n=14) | 3,8%, 4,6% |
| 02 | 6,3% (n=19) | 5,8%, 6,9% | 3,9% (n=6) | 3,5%, 4,4% |
| 03 | 6,3% (n=19) | 5,8%, 6,9% | 4,6% (n=7) | 4,2%, 5,0% |
| 04 | 6,3% (n=19) | 5,8%, 6,9% | 8,5% (n=13) | 7,9%, 9,1% |
| 05 | 4,6% (n=14) | 4,2%, 5,1% | 6,6% (n=11) | 6,1%, 7,2% |
| 06 | 4,0% (n=12) | 3,6%, 4,4% | 6,4% (n=11) | 5,9%, 6,9% |
| 07 | 4,3% (n=13) | 3,9%, 4,8% | 3,3% (n=5) | 2,9%, 3,7% |
| 08 | 3,3% (n=10) | 3,0%, 3,7% | 2,0% (n=3) | 1,7%, 2,3% |
| 09 | 4,0% (n=12) | 3,6%, 4,4% | 3,9% (n=6) | 3,5%, 4,4% |
| 10 | 4,0% (n=12) | 3,6%, 4,5% | 5,6% (n=20) | 5,1%, 6,1% |
| 11 | 2,7% (n=8) | 2,3%, 3,0% | 4,0% (n=7) | 3,6%, 4,5% |
| 12 | 3,0% (n=9) | 2,7%, 3,4% | 1,5% (n=7) | 1,2%, 1,7% |
| 13 | 3,7% (n=11) | 3,3%, 4,1% | 3,5% (n=15) | 3,1%, 4,0% |
| 14 | 5,0% (n=15) | 4,6%, 5,5% | 4,0% (n=19) | 3,6%, 4,4% |
| 15 | 4,4% (n=13) | 3,9%, 4,8% | 4,3% (n=24) | 3,9%, 4,7% |
| 16 | 2,3% (n=7) | 2,0%, 2,7% | 2,7% (n=12) | 2,4%, 3,1% |
| 17 | 5,0% (n=15) | 4,6%, 5,5% | 4,4% (n=15) | 4,0%, 4,8% |
| 18 | 5,0% (n=15) | 4,6%, 5,5% | 3,5% (n=12) | 3,2%, 4,0% |
| 19 | 2,3% (n=7) | 2,0%, 2,7% | 2,6% (n=6) | 2,2%, 2,9% |
| 20 | 4,0% (n=12) | 3,6%, 4,5% | 3,0% (n=9) | 2,7%, 3,4% |
| 21 | 1,3% (n=4) | 1,1%, 1,6% | 2,1% (n=7) | 1,8%, 2,4% |
| 22 | 4,7% (n=14) | 4,3%, 5,2% | 3,1% (n=13) | 2,8%, 3,5% |
| 23 | 5,0% (n=15) | 4,6%, 5,5% | 4,6% (n=26) | 4,1%, 5,0% |
| 24 | 2,7% (n=8) | 2,3%, 3,0% | 5,8% (n=22) | 5,3%, 6,3% |
| 25 | 3,0% (n=9) | 2,7%, 3,4% | 2,1% (n=10) | 1,8%, 2,4% |
| ambito | ||||
| Urbano | 65,4% (n=197) | 65%, 65% | 65% (n=100) | 65%, 65% |
| Rural Disperso | 25,7% (n=77) | 26%, 26% | 26% (n=100) | 26%, 26% |
| Rural Agrupado | 8,8% (n=26) | 8,8%, 8,8% | 8,8% (n=100) | 8,8%, 8,8% |
| Abreviacion: CI = Intervalo de confianza | ||||
| 1 Media (DE); % (n sin ponderar) | ||||
3.5 Muestreo por Clústers
El muestreo por clúster es otra manera de aplicar el azar para diseñar muestras. A diferencia del muestreo estratificado en el muestreo por clúster el investigador considera a estos como “racimos” de casos que, usualmente, se encuentran cercanos geográficamente pero no necesariamente socialmente o, más en general, no son homogéneos en las variables de estudio. En efecto, la ventaja de este tipo de muestreo es que abarata costos en la ejecución de muestras espacialmente extensas y especialmente si en ese espacio extenso hay numerosos racimos de casos como, por ejemplo, una multitud de pequeños poblados urbanos de 50.000 personas. El precio que usualmente se paga (a igual cantidad de casos) es un aumento en el error standard pero, justamente, el quid de la cuestión es que dado la baja del costo unitario de cada caso ahora es posible, con igual presupuesto, agregar más casos a la muestra para bajar la precisión hasta el valor deseado.
3.6 Muestreo Proporcional al Tamaño (PPS)
Muchas veces, especialmente en diseños polietápicos, se desea que en la primera etapa las unidades de selección (llamadas justamente unidades de selección primarias) sean escogidas en función de alguna variable que sirva como indicador de su tamaño. Esta técnica se suele denominar muestreo proporcional al tamaño (PPS)3 y puede considerarse como un caso especial del muestreo por clústers (Lumley 2010, pág. 46). En el caso de unidades geográficas esa variable podrá ser el tamaño espacial o área (p.e. km2) y en variables no espaciales podrá ser la cantidad de personas (p.e. votantes en distritos). En el caso de una muestra de colegios, variables como el tamaño de la matrícula pueden ser buenas candidatas a utilizar en este tipo de muestras.
Un PPS, por diseño, va a otorgar una mayor probabilidad de salir en la muestra a los colegios con mayor matrícula y estos pueden poseer características particulares como, por ejemplo, encontrarse abrumadoramente en ámbitos urbanos. De este modo ya podemos intuir que, con respecto a la población de establecimientos, una muestra PPS (sin ponderar) obtendrá como resultado una sobrerrepresentación de los establecimientos de ámbito urbano y, estarán sobrerrepresentados aquellos establecimeintos con mayor matrícula. Aunque parezca algo paradójico esto es justamente para darles a todos los estudiantes (y no solo los del ámbito urbano) una misma chance de salir en la muestra. Esto último depende, especialmente en un diseño polietápico, que se haga efectivamente después de haber realizado la selección primaria, esto es, que se haga después de la primera etapa.
A pesar de cierta idea intuitiva acerca del objetivo del muestreo PPS, su efectiva aplicación (especialmente en muestreos sin reemplazo) tiene sus complejidades a nivel de los algoritmos a utilizar. Esto en parte es algo compartido por todos los muestreos sin reemplazo (versus los con reemplazos) pero aquí está presente la dificultad adicional de que las probabilidades de inclusión son diferentes. En efecto, el muestreo PPS puede ser considerado como un tipo de muestreo con probabilidades de inclusión diferentes (unequal probabilities) pero con la particularidad que esas probabilidades diferentes se calculan en función del tamaño de las unidades a seleccionar en primera instancia. A continuación vamos a utilizar un algoritmo que tiene que ver con la idea de “local pivotal” que vamos a ver con mayor profundidad cuando veamos las muestras bien dispersas (sec-bien_distribuido)4.
Para visualizar esto vamos primero vamos a construir a realizar 2 ejemplos. Uno en donde se realiza un PPS en donde luego solo se expande por un ponderador que simula que todos los establecimientos tenían las mismas chances de haber entrado (o, expresado de otro modo, que expande pero no pondera) y otro en donde, a esa misma muestra, se la pondera por la probabilidad inversa de haber ingresado en la muestra, esto es, un ponderador que haga pesar menos a aquellos establecimientos con mayor tamaño. Siguiendo con el ejemplo de los colegios, si el proceso es seleccionar los colegios por tamaño y luego realizar un censo (esto es, ninguna muestra) de estudiantes dentro de cada uno de los colegios seleccionados, tanto los colegios como los estudiantes de ámbito urbano se encontrarán sobrerrepresentados por lo que un ponderador que tenga en cuenta las probabilidades inversas en función del tamaño puede ser útil.
| Característica |
PPS expandida pero no ponderada
|
PPS ponderada por PI en función del tamaño
|
|
|---|---|---|---|
| N = 4.1591 | N = 4.0121 | 95% CI | |
| matricula | 529,5 (2,90) | 277,7 (9,08) | 260, 296 |
| secciones | 19,7 (0,08) | 11,6 (0,34) | 11, 12 |
| sondeo_primero | 54,1 (0,13) | 58,6 (1,12) | 56, 61 |
| Desconocido | 83 | 153 | |
| sondeo_segundo | 67,9 (0,12) | 74,2 (0,65) | 73, 75 |
| Desconocido | 97 | 678 | |
| region | |||
| 01 | 6,3% (n=19) | 4,7% (n=19) | 4,2%, 5,3% |
| 02 | 7,0% (n=21) | 4,5% (n=21) | 4,0%, 5,0% |
| 03 | 9,7% (n=29) | 5,5% (n=29) | 5,0%, 6,1% |
| 04 | 13,7% (n=41) | 7,6% (n=41) | 6,9%, 8,3% |
| 05 | 7,0% (n=21) | 3,4% (n=21) | 3,0%, 3,7% |
| 06 | 3,7% (n=11) | 3,3% (n=11) | 2,9%, 3,8% |
| 07 | 2,7% (n=8) | 2,6% (n=8) | 2,2%, 3,0% |
| 08 | 5,7% (n=17) | 2,8% (n=17) | 2,5%, 3,2% |
| 09 | 11,3% (n=34) | 4,9% (n=34) | 4,4%, 5,4% |
| 10 | 5,0% (n=15) | 4,1% (n=15) | 3,6%, 4,7% |
| 11 | 5,0% (n=15) | 3,6% (n=15) | 3,1%, 4,1% |
| 12 | 2,0% (n=6) | 3,5% (n=6) | 2,8%, 4,3% |
| 13 | 1,3% (n=4) | 3,9% (n=4) | 3,0%, 5,0% |
| 14 | 3,0% (n=9) | 2,3% (n=9) | 1,9%, 2,6% |
| 15 | 2,3% (n=7) | 3,4% (n=7) | 2,8%, 4,1% |
| 16 | 0,0% (n=0) | 0,0% (n=0) | 0,00%, 0,00% |
| 17 | 0,7% (n=2) | 1,3% (n=2) | 0,95%, 1,7% |
| 18 | 3,7% (n=11) | 14,6% (n=11) | 11%, 18% |
| 19 | 1,3% (n=4) | 1,2% (n=4) | 0,98%, 1,5% |
| 20 | 1,3% (n=4) | 1,6% (n=4) | 1,2%, 2,0% |
| 21 | 1,3% (n=4) | 1,7% (n=4) | 1,3%, 2,1% |
| 22 | 2,3% (n=7) | 1,6% (n=7) | 1,3%, 1,8% |
| 23 | 1,3% (n=4) | 3,9% (n=4) | 3,1%, 5,0% |
| 24 | 0,7% (n=2) | 0,4% (n=2) | 0,33%, 0,58% |
| 25 | 1,7% (n=5) | 14,0% (n=5) | 10%, 19% |
| ambito | |||
| Urbano | 95,3% (n=286) | 62,1% (n=286) | 58%, 66% |
| Rural Disperso | 1,7% (n=5) | 25,2% (n=5) | 21%, 30% |
| Rural Agrupado | 3,0% (n=9) | 12,7% (n=9) | 11%, 15% |
| Abreviacion: CI = Intervalo de confianza | |||
| 1 Media (EST); % (n sin ponderar) | |||
En efecto, en la Tabla tbl-pps_ponderadores puede observarse que si trabajamos en una muestra PPS solo expandiendo pero sin ponderar (primera tabla desde la izquierda) vemos como el valor promedio de la matrícula es alto (529) y que la abrumadora mayoría de los establecimientos seleccionados son del ámbito urbano (95%). Si luego analizamos la muestra ponderada por la probabilidad inversa en función del tamaño vemos como la mayoría de los valores se acercan a los valores conocidos de la población, especialmente aquellos que refieren a propiedades intrínsecas de los establecimientos como la región y el ámbito. Sin embargo, esta operación tiene sus riesgos porque hace depender mucho al ponderador de la matrícula y esta puede ser sumamente heterogénea. Por poner un ejemplo, en el muestreo PPS fueron seleccionados 5 establecimientos de la región 25 que es una región que se caracteriza por tener un porcentaje de establecimientos rurales mayor a la media (alrededor del 40% son urbanos). Pero dado que en el PPS los establecimientos más grandes tienen más chances de entrar en la muestra se seleccionaron 4 establecimientos urbanos (con matrícula típica de ámbitos urbanos) y solo 1 de ámbito rural. En este contexto el ponderador luego hace que esos 4 pesen menos y que ese único establecimiento rural (que tiene una matrícula de 7 estudiantes) pese mucho más que lo que descuentan los 4 urbanos. El resultado es que la región 25, cuando se trabaja con el ponderador, salta desde un 1,7% sin ponderar hasta un 14% ponderado. Algo similar sucede con la región 18. Por esta razón, es interesante también observar que en muchos casos el intervalo de confianza con la muestra ponderada se expande (p.e. región 18 y 25). Esto se debe a que el ponderador ahora hace pesar más en la estimación a situaciones en donde se encuentran pocos casos y, por lo tanto, al estar basadas en menos casos esas estimaciones poseen un margen de error mayor.
Si en cambio, luego en una segunda etapa, se realiza un muestro de una cantidad fija (p.e. 10 estudiantes por colegio seleccionado) la muestra de colegios sin ponderar seguirá sobrerrepresentando a los establecimientos del ámbito urbano pero tiene muchas chances de representar aceptablemente a la población de estudiantes. Esto último justamente una de las características más aprecidas del PPS en diseños polietápicos. En efecto, aplicado al mundo educativo, puede ser algo buscado explícitamente si se utiliza la selección de los colegios como unidades de selección primarias y luego a los estudiantes como unidades de selección secundaria o final. En otras palabras, se trata de un efecto buscado por diseño, justamente porque ahora el objetivo está puesto en lograr una muestra representativa de la población de estudiantes a través de una población de establecimientos que contiene variables agregadas de los estudiantes.
Para fijar las ideas, en el ejemplo anterior se seleccionarían en primera instancia unos 300 establecimientos, luego se obtendría una muestra final de 3000 estudiantes porque en la segunda instancia se seleccionaron 10 estudiantes por establecimiento. Una virtud práctica de este último ejemplo es que, aparte de reducir costos de logística en comparación a un muestreo por azar simple de un solo paso (porque se van a menos unidades de selección primarias), es que otorga un mismo ponderador a cada caso seleccionado (se dice que la muestra es autoponderada) lo que facilita muchos análisis posteriores. Esto es un típico ejemplo de muestra compleja en donde la muestra se realiza en más de una etapa y en cada una de ellas se utilizan técnicas diferentes.
En relación con lo anterior y de manera aparentemente paradójica, la muestra PPS sin ponderar estima mejor las variables agregadas como el valor del primer y segundo sondeo que un análisis censal de toda la población de colegios (como se hizo en Tabla tbl-parametros_base). Lo paradógico de esto es que una muestra, esto es, una parte de un todo, logre un mejor acercamiento a un respectivo parámetro poblacional que un censo, esto es, un registro de cada una de las partes del todo. La solución a esta paradoja es entender que la Tabla tbl-parametros_base hace referencia a la población de colegios y, en ese sentido, sus valores son correctos. Ahora bien, si con esos datos (censales, pero de la población de establecimientos) se quiere hacer afirmaciones sobre la población de estudiantes la información de la Tabla tbl-parametros_base no es la más idónea o, al menos, hay que tratarla de manera diferente. En las variables que se pueden considerar como variables agregadas de estudiantes (p.e. sondeo_primero, sondeo_segundo) más que calcular la media habría que haber calculado la media ponderada por matrícula y ese cálculo sería un mejor estimador de la media de las notas de la población de estudiantes En ese caso, el resultado de ese cálculo sí se podría considerar como un parámetro de la población de estudiantes y contra esos valores se debería comparar las estimaciones del diseño PPS sin ponderar. Esto precisamente se puede observar en la Tabla tbl-media_ponderada_notas_estudiantes.
| Característica |
PPS sin ponderar
|
Pob. media ponderada
|
Pob. media sin ponderar
|
|---|---|---|---|
| sondeo_primero | 54 | 54 | 57 |
| sondeo_segundo | 68 | 68 | 70 |
Brus, Dick. 2022. Spatial sampling with R. Chapman & Hall /CRC.
Everitt, Brian, Sabine Landau, Morven Leese, y Daniel Stahl. 2011. Cluster Analysis. 5 Edition. Wiley.
Kish, Leslie. 1980. «Design and estimations for domains». The Statistician 29 (4): 209-22.
Lumley, Thomas. 2010. Complex surveys. A guide to analysis using R. John Wiley & Sons.
Neyman, Jerzy. 1934. «On the Two Different Aspects of the Representative Method: The Method of Stratified Sampling and the Method of Purposive Selection». Journal of the Royal Statistical Society 97 (4): 558-625.
Platón. 2002 [370AVC]. Phaedrus. Oxford University Press.
Tillé, Yves, y Alina Matei. 2023. Package "sampling".
Si el conjunto de los estudiantes (así como los maestros y los directivos) de la provincia hubiera sido sorteado para ingresar a cualquier colegio de la provincia y si todos los colegios tendrían la misma matrícula (así como maestros y directivos), realizar una muestra aleatoria de colegios con el objetivo de realizar una muestra aleatoria de estudiantes (o de maestros y directivos) no sería un mayor problema. El primer criterio tiene que ver con las diferencias de cada colegio y el segundo con el modo de agregar esas diferencias en una muestra cuyo primer paso es la selección de unidades agregadas (colegios) para estimar valores de unidades de selección menores (estudiantes, maestras y directivos).↩︎
Un dominio o subclase de estimación es una partición de la población o de la muestra sobre la cual se espera realizar inferencias. A veces se usa la denominación que los dominios denotan subpoblaciones (de la población) y las subclases reflejan esas divisiones en la muestra (Kish 1980, 209). En cualquier caso es conveniente introducir estos dominios en el diseño de la muestra para poder controlar su tamaño poblacional (Brus 2022, cap. 14). En el ejemplo del cuerpo del texto se asume que esos dominios de estimación coinciden con los estratos aunque esto no tiene nada de necesario.↩︎
La sigla PPS viene de la expresión “Probability Proportional to Size” que es como se lo conoce en la bibliografía de muestreo.↩︎
Existen otros algoritmos para realizar un muestreo PPS. Muchos de ellos son algoritmos especializados en probabilidades desiguales (en donde la desigualdad por tamaño sería un caso especial) por lo que muchos de sus nombres suelen empezar con UP (unequal probabilities). Algunos son los siguientes: UPtille, UPpivotal, UPpoisson (Tillé y Matei 2023).↩︎